Inhaltsverzeichnis
Einsatzmöglichkeiten von Zabbix
Monitoring Lösungen
Mit wachsenden Systemlandschaften und zunehmender Komplexität der Anwendungen führt mittlerweile kein Weg mehr an Überwachungs- und Kontrollmechanismen vorbei, um einen stabilen Betrieb von IT-Systemen zu gewährleisten. Die Zeiten sind lange vorbei als Administratoren eigenständig eine Nagios-Installation aufsetzten, um ihre alltäglichen Aufgaben effizienter und routinierter bewältigen zu können. Heute überblicken IT-Verantwortliche ihren Arbeitsbereich mit sekundengenauen Dashboards und nutzen aussagekräftige Reports zur Bewertung und Analyse der Systeme. Aber auch abseits der klassischen Betreuung von IT-Landschaften hat Monitoring in vielen Bereichen einen festen Platz. Die fortlaufende Messung und Prüfung von Daten ermöglicht es Zusammenhänge aufzudecken und anhand festgestellter Tendenzen schnell Reaktionen einzuleiten. In Zeiten von Big Data haben sich dadurch ganz neue Geschäftsfelder rund um die Gewinnung und Auswertung von Informationen etabliert.
In diesem Beitrag möchte ich generell auf Aspekte von Monitoring-Lösungen speziell im Bereich der IT-Systemadministration eingehen und Erwartungen sowie Realisierungsschwierigkeiten aufzeigen. Anschließend werde ich die Open-Source-Software Zabbix vorstellen und anhand ausgewählter Beispiele Realisierungsmöglichkeiten demonstrieren. Letztere sollen auch den offenen Ansatz und die freie Konfigurierbarkeit von Zabbix verdeutlichen, wodurch sich die Software in vielen Anwendungsfällen für Monitoringaufgaben außerhalb der IT-Administration einsetzen lässt.
Wer auf automatisierte Überwachungssysteme setzt, verfolgt damit in aller Regel einen bestimmten Zweck. Monitoring-Lösungen werden häufig eingeführt, um gegen bestehende Probleme vorzugehen. Sie sollen Fehler zeitnah aufdecken – idealerweise bevor daraus Ausfälle resultieren. Die Überwachung ähnlicher Geräte oder Anwendungen nach identischem Schema ermöglicht ein hohes Maß an Skalierbarkeit bei nahezu gleichbleibendem Aufwand. Ebenso ist es einer Monitoring-Software weitgehen egal ob sie 2-3 Merkmale prüft oder ein paar Dutzend Sensoren auswertet. Der zusätzliche Informationsgewinn erlaubt dem versierten Anwender aber viel detaillierte Analysen – z.B. im Rahmen der Fehlersuche. Und die fortlaufende Erfassung und Protokollierung aller Vorgänge ist nicht an Bürozeiten gebunden und stellt dadurch sicher, dass später auch Daten vorliegen, wenn diese für einen bestimmten Zeitpunkt benötigt werden. Nicht zuletzt spielen nicht selten auch Erwartungen eine Rolle, mit weniger Personal mehr Aufgaben mit gleichbleibender oder sogar höherer Gründlichkeit bewältigen zu können.
Den zuvor genannten Zielen stehen in der Praxis allerdings regelmäßig Schwierigkeiten und Unzulänglichkeiten gegenüber, die den Nutzen und Mehrwert des Monitorings in Frage stellen. So wird der Einrichtungsaufwand einer automatisierten Lösung oftmals unterschätzt. Dieser ist in der Regel – entgegen häufiger Erwartungen – gerade nicht nach Installation einer Monitoring-Software in ihrem Auslieferzustand erledigt. Umfang und Aussagekraft der Prüfungen lassen mit der Grundversion des Produkts doch meist zu wünschen übrig. So bekommt man schnell oberflächliche Informationen über die zu überwachenden Geräte, wie z.B. Prozessorauslastung, Speicherbelegung oder eine Verfügbarkeitsprüfung mittels Netzwerk-Ping. Einen echten Mehrwert bieten diese dem Administrator für seine alltäglichen Aufgaben aber nur sehr begrenzt. Was nützt ihm die Anzeige, dass die Prozessorauslastung im grünen Bereich ist, wenn die benötigte Anwendung z.B. in Folge eines Absturzes nicht mehr verfügbar ist? Oder die Aussage, dass der Arbeitsspeicher komplett genutzt ist ohne Kenntnis darüber zu liefern, dass über die Hälfte davon vom Betriebssystem als Datei-Cache genutzt wird, weil er gerade anderweitig nicht benötigt wird. Ebenso vermittelt eine simple Netzwerkverfügbarkeit mittels Ping eine trügerische Sicherheit, wenn die kritischen Dienste nicht geprüft werden.
Leider werden Monitoring-Lösungen darüber hinaus nicht selten von Anwendern bedient, denen ein tiefergehender fachlicher Hintergrund fehlt. Das mag bei einem professionell eingerichteten und konfigurierten System noch funktionieren. Hier können Mitarbeiter im First Level Support tatsächlich Fehler diagnostizieren, die sie selbst niemals aufgedeckt oder schlussgefolgert hätten. Allerdings müssen die automatisierten Prüfungen dazu vorher wohlüberlegt erstellt und mit ausreichender Tiefe angelegt worden sein. Die Anschaffung einer Monitoring-Software allein ersetzt normalerweise keinen erfahrenen Administrator. Nur wer seine Systemlandschaft genau kennt, weiß welche Aspekte in das Monitoring aufgenommen werden müssen. Und dieses fachliche Knowhow ist auch im fortlaufenden Betrieb von Nöten, damit die Überwachung mitwächst mit Veränderungen und Erweiterungen auf Server-, Netzwerk- oder Anwendungsseite.

Um die problembehafteten Aufzählungen zu Ende zu bringen, noch ein Aspekt, der in der Praxis gern vernachlässigt wird: der Einsatz von Monitoring-Software entbindet nicht von Verantwortung und Zuständigkeiten. So sollte klar feststehen, wer sich um die Aufrechterhaltung und fortlaufende Pflege des Überwachungssystems kümmert. Daneben müssen aber auch eindeutige Regeln existieren, wie mit Meldungen des Monitorings umgegangen wird, wer darauf einen Blick haben muss und bei Bedarf tätig wird. Die alleinige Feststellung von Problemen ohne eine zeitnahe Betrachtung und Behebung ergibt sonst keinen wirklichen Mehrwert.
Berücksichtigt man die vorangehenden Praxis-Probleme, wird schnell klar, dass der Auswahl der geeigneten Software zur Systemüberwachung eine entscheidende Rolle zukommt. Dazu sollte man zuerst gründlich ermitteln, welche Geräte, Anwendungen, Dienst, etc. alles von der Monitoring-Lösung erfasst und geprüft werden sollen. So kann es durchaus Sinn machen, eine kostspiele Speziallösung einzukaufen, wenn ausschließlich Netzwerkinfrastruktur im Fokus der Prüfung steht, für deren Auswertung ein fertiges und mitwachsendes Produkt existiert. Entscheidet man sich andererseits vorschnell für eine Monitoring-Software, kann es passieren, dass sich damit später Teile der Systemlandschaft gar nicht oder nur mit großem Aufwand bzw. unbefriedigendem Ergebnis auswerten lassen. Ein Aspekt sind in der Regel natürlich auch die Anschaffungskosten, wobei man hier teilweise unterscheiden muss zwischen Produkten mit einmaligem Kaufpreis und Mietmodellen, die kontinuierlich bezahlt werden wollen, auf der anderen Seite. Neben lizenzpflichtiger Software gibt es aber auch unterschiedliche Open Source Produkte, die mit ihrer freien Verfügbarkeit punkten. Je nach Anwendungsfall kann bei letzteren auch die offene Code-Basis für individuelle Anpassungen und Erweiterungen einen entscheidenden Vorteil darstellen. Viel wichtiger als die Frage der Anschaffungskosten sollte es aber sein, zu klären, wer das System anschließend betreuen soll, welches Knowhow vorhanden ist und welche Ressourcen – insbesondere Arbeitszeit – dafür zur Verfügung gestellt werden kann. Das schränkt die Auswahl infrage kommender Produkte und Realisierungsmöglichkeiten evtl. bereits von Haus aus ein.
Monitoring Software Zabbix
Wie zu Beginn angekündigt, werde ich im zweiten Teil nun die Monitoring Software Zabbix vorstellen. Die Open Source Software stellt eine umfassende Lösung zur Überwachung von IT-Systemen dar und erfreut sich unter Administratoren großer Beliebtheit. Für die Erfassung von Daten bietet Zabbix mehrere Schnittstellen. Den größten Funktionsumfang bietet die Installation eines sog. Agenten auf dem zu überwachenden Gerät. Bei einem Agenten handelt es sich um einen Software-Client, der Daten an den Zabbix-Server liefert. Dies kann wahlweise passiv (per Poll-Abfrage) oder aktiv (per Push-Übertragung) erfolgen. Zabbix-Agenten gibt es für eine Vielzahl Betriebssysteme, insbesondere Linux, Windows, OSX, AIX und FreeBSD bzw. OpenBSD. Daneben existieren weitere Schnittstellen für Sensorabfragen, wie SNMP, IPMI und JMX.
Neben der freien Verfügbarkeit überzeugt Zabbix durch seine Erweiterungsmöglichkeiten und den enormen Funktionsumfang. Die Komplexität fordert ihren Preis in Form erhöhten Einarbeitungs- und Lernaufwands, der sich jedoch schnell bezahlt macht. Ein bestechendes Merkmal, mit dem sich Zabbix von anderen Open Source Monitoring-Lösungen absetzt, ist die mächtige Weboberfläche. Diese erlaubt für Alltagsaufgaben eine reine webbasierte Bedienung, ohne die Notwendigkeit der umständlichen Konfigurationspflege in Textdateien, wie man dies beispielsweise vom oben erwähnten Nagios/Icinga kennt. Die Weboberfläche bietet direkten Zugriff auf Merkmale wie anpassbare Dashboards (Screens), Topologiedarstellungen (Maps) mit integriertem Editor, Inventarisierung der Geräte (Hosts), automatische Host-Erkennung (Discovery) sowie eine spezielle Komponente zur Prüfung von Webanwendungen.
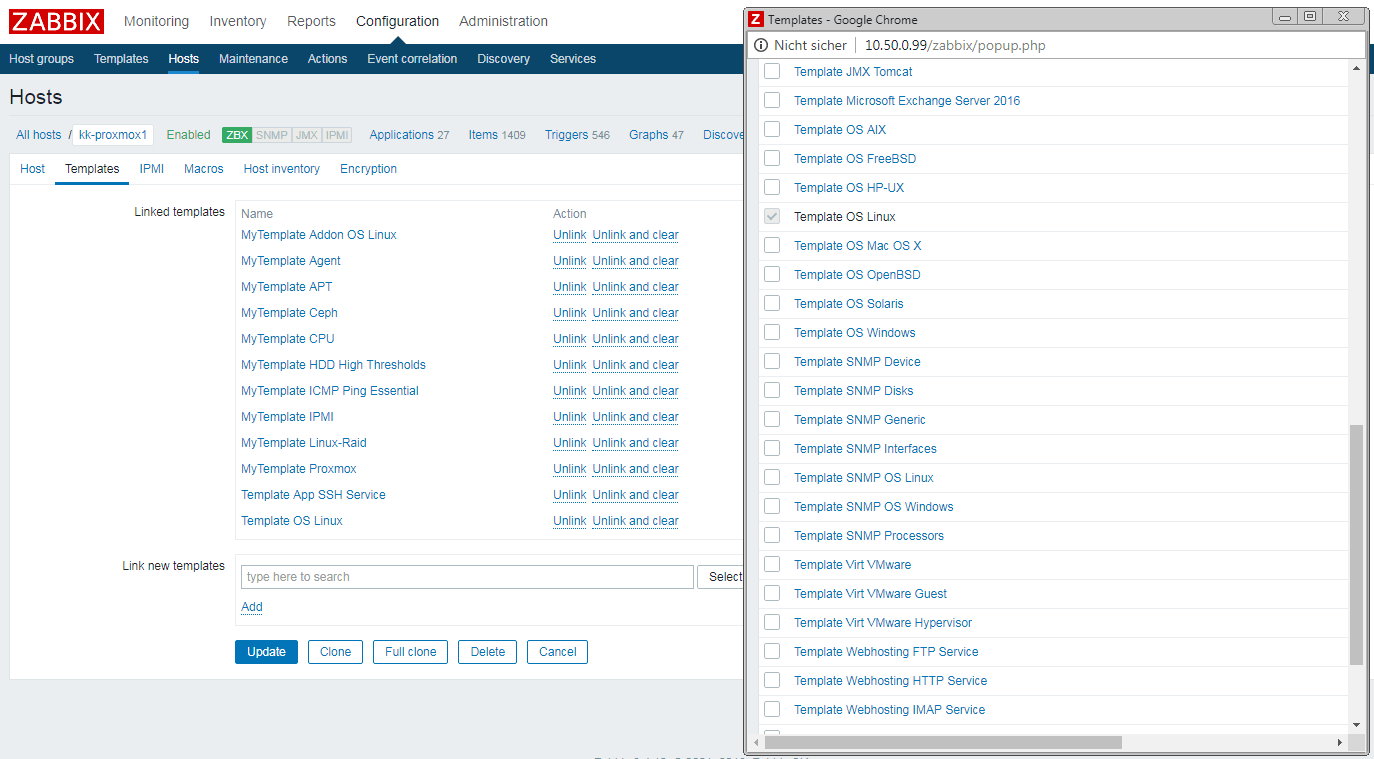
Überzeugend ist bei Zabbix die Einrichtung der Prüfungsaufgaben gelöst. Einzelne Prüfungen werden in Zabbix als Items bezeichnet. Allerdings wird man in der Praxis nur selten einzelne Überprüfungen definieren. Stattdessen findet man Items zusammengefasst nach ihrem Einsatzzweck, Anwendung oder Betriebssystembasis des jeweiligen Geräts (Zabbix-Bezeichnung: Host) in Form von Gruppen, den sog. Templates. Diese Abstraktion erlaubt es auf sehr einfache und effiziente Weise neue Geräte in die Überwachung mit aufzunehmen. Nach Definition der Grundmerkmale wie Name oder IP-Adresse eines Geräts, sucht man sich passende Templates aus dem Pool der eigenen Zabbix-Installation aus, z.B. ein Template für das entsprechende Betriebssystem sowie weitere Templates zur Prüfung bereitgestellter Dienste. Templates stellen daher das A und O für eine leistungsstarke Zabbix Installation dar. Verfügt man erst einmal über einen breiten Pool unterschiedlichster Prüfungsszenarien, wird Zabbix zum mächtigen Datensammler und erlaubt auf komfortable Weise die Erweiterung um neue Hosts aber auch die Ausrollung weiterer Prüfungen. Templates werden von offizieller Seite aber auch rege durch die Anwender-Community bereitgestellt (unter share.zabbix.com). Wer sich wirklich ernsthaft mit dem Monitoring seiner Systemlandschaft beschäftigt, wird aber wohl früher oder später beginnen, sich seine eigenen Templates zu schreiben. Ab hier wird man in der Regel doch noch Konfigurationsdateien pflegen müssen. Hat man sein individuelles Template aber erst einmal erstellt, steht es ab sofort zur bequemen Ausrollung über die Weboberfläche bereits. Das offene Template-Konzept ermöglicht es auch Zabbix für Prüfungsaufgaben außerhalb der IT-Administration einsetzen.
Als Ergänzung zu den Items, die zunächst nur zur Datenerfassung dienen, bietet Zabbix als logische Fortführung die Möglichkeit Alarmierungen z.B. bei Überschreitung eines Schwellenwerts durch ein Item festzulegen. Diese Alarmierungen werden als Trigger bezeichnet. Items und Trigger sind dadurch eng verknüpft bzw. bauen aufeinander auf. Auch bei der Definition von Triggern erlaubt Zabbix größtmögliche Freiheit. So können Items selbstverständlich in unterschiedlichen Triggern abgefragt werden und die Prüf- bzw. Vergleichsmöglichkeiten von Triggern unterstützen auch zahlreiche komplexere Funktionen, z.B. Summen- oder Mittelwertbildungen oder Vergleiche über frei definierbare Perioden. Letzteres ermöglicht es beispielsweise schleichende Veränderungen in Messwerten aufzudecken durch Vergleiche mit gemittelten Sensordaten vom Vortag oder der vorangegangenen Woche.
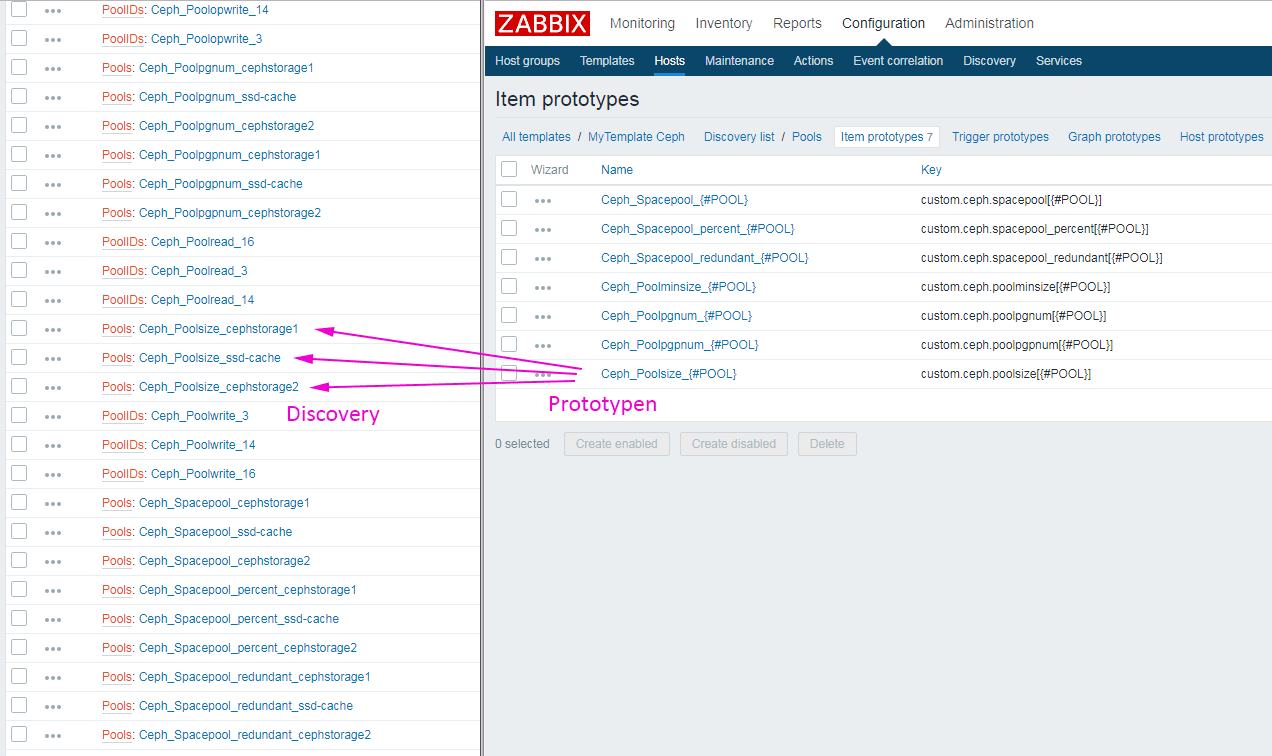
Als herausragendes Merkmal kann man die Erstellung dynamischer Items und Trigger durch Zabbix-Templates bezeichnen. Nehmen wir als Beispiel ein Template zur Erfassung der Festplattentemperatur. Die meisten Zielgeräte werden über mehr als 1 Festplatte verfügen. Mit statischen Items und Trigger könnte man Prüfungen für eine bestimmte Zahl von Festplatten vorsehen, z.B. 4 Stück. Bei Geräten mit weniger als 4 Festplatten würde dies zu leeren bzw. unerfüllten Items und Trigger führen. Auf anderen Geräten, die über mehr als 4 Festplatten verfügen, blieben hingegen Komponenten unberücksichtigt. Man könnte nun separate Templates für unterschiedliche Festplattenbestückungen erstellen. Das ist in Zabbix aber gar nicht erforderlich, da Templates von Haus aus dynamische Items und Trigger unterstützen – abhängig von der tatsächlich vorgefundenen Zahl an Einzelkomponenten. Die Ermittlung dieser Komponenten (in unserem Beispiel: die Anzahl der Festplatten im Host) bezeichnet man in Zabbix als Discovery. Dahinter verbirgt sich eine relativ einfach zu implementieren Erkennungsroutine, die dem Zabbix-Template die tatsächlich vorhandenen Einzelkomponenten in Form eines JSON-Array zurückliefert. Für alle Einträge im JSON-Array lassen sich dann dynamisch Items und Trigger vordefinieren. So reicht ein einzelnes, wohlüberlegtes Template in Zabbix aus, um einen ganzen Anwendungsfall universell abzudecken.
Eine konsequente Fortführung der Alarmierung durch Trigger bietet Zabbix durch die Möglichkeit automatische Aktionen (Actions) zu erstellen. Erkennt z.B. ein Trigger den Ausfall eines Dienstes auf einem Host (z.B. der DNS-Server antwortet nicht mehr), kann durch eine zuvor festgelegte Aktion automatisch der Service neu gestartet werden. Im Alltag lassen sich so Routinefälle ohne menschlichen Eingriff beheben. Benachrichtigungen über Probleme und deren Lösung, wie man sie von einer Monitoring-Software erwartet, sind in Zabbix ebenfalls als Aktionen ausgeführt. Dies bietet den Vorteil mehrstufige Prozesse definieren zu können, bei denen zunächst eine automatische Fehlerbehebung ausgelöst wird, bevor eine E-Mail-Benachrichtigung an das Support-Team erfolgt und – bei Fortbestand der Störung – weitere Eskalationen erfolgen, z.B. E-Mails an die Team-Leitung oder SMS-Benachrichtigungen. Da auch Aktionen Optionen zur freien Erweiterbarkeit mitbringen, ist es z.B. relativ einfach möglich externe Systeme anzubinden (z.B. ein Ticket-System) oder weitere Kommunikationsmedien (z.B. Benachrichtigungen via Telegram) einzubinden.
Beim Schlagwort der freien Erweiterbarkeit sollte auch die Skripting-Schnittstelle von Zabbix nicht unerwähnt bleiben. Eine besonders effektive Lösung zur Bedienung der Zabbix-API stellt hier das Python-Skript Zabbix-CLI dar, mit dem sich beispielsweise vollautomatisiert Hosts in Zabbix erstellen lassen – mit vordefinierten Konfigurationseigenschaften aus XML-Dateien. Wer sich die Zeit nimmt, Routine-Tätigkeiten wie die Einbindung neuer Hosts (von bekanntem Typ) durch Automatismen zu bedienen, dem bietet Zabbix spätestens an dieser Stelle größtmögliche Effizienz und Einsparpotenziale.
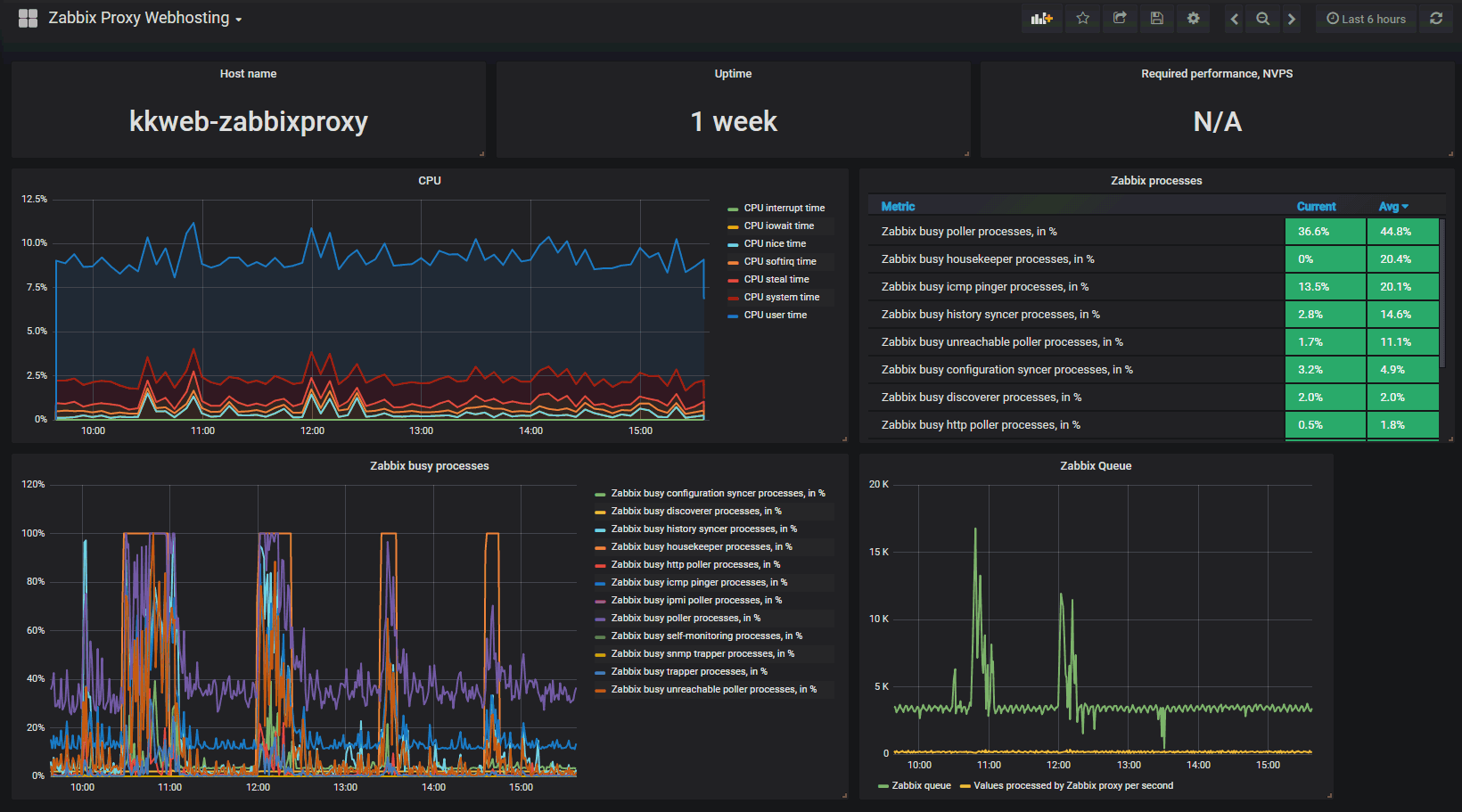
Als letztes bestechendes Merkmal eines Monitoring-Systems mit Zabbix sei noch auf die Schnittstellenintegration in Grafana hingewiesen. Bei Grafana handelt es sich um eine mächtige Open Source Software zur Datenvisualisierung, mit der sich wunderschöne, intuitiv bedienbare Dashboards und Auswertungen erstellen lassen. Eine Vorstellung von Grafana ist in einem eigenen, späteren Beitrag geplant. Ergänzt man die Monitoring-Funktionalität von Zabbix mit den Visualisierungsmöglichkeiten von Grafana, erhält man ein Gesamtsystem, das sowohl auf Überwachungsseite wie auch im Bereich der optischen Darstellung seinesgleichen sucht.
Einsatzmöglichkeiten von Zabbix
Nach der Theorie möchte ich nun, wie eingangs angekündigt, anhand von 3 ausgewählten Beispielen die Einsatzmöglichkeiten von Zabbix demonstrieren. Da dieser Beitrag einen Überblick zu den Möglichkeiten von Monitoring und Zabbix geben soll, kann er keine Einführung in die Bedienung und Grundkonfiguration der Überwachungssoftware geben. Hier sei auf die Vielzahl an Artikeln, Tutorials und die umfangreiche Zabbix-Dokumentation verwiesen.
Beispiel 1: Screens und Maps
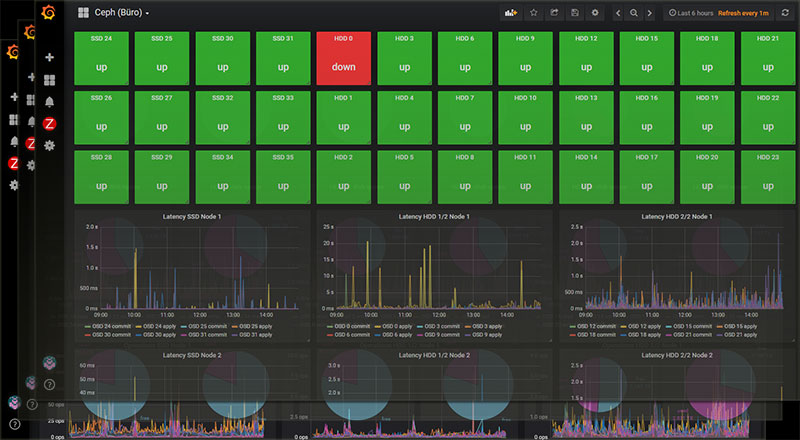
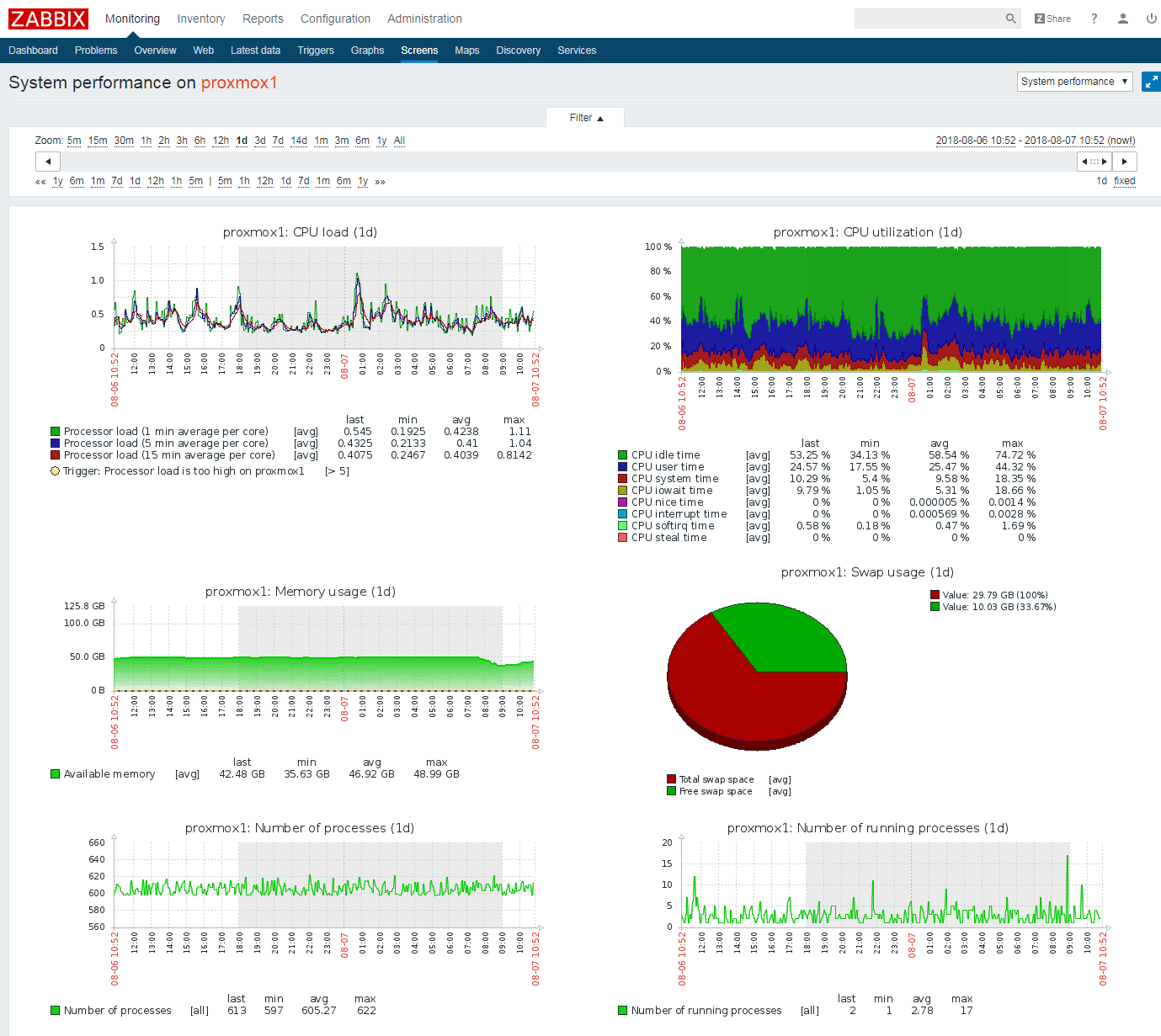
Mit Screens bietet Zabbix die Möglichkeit individuelle Dashboards zu erstellen. Die nachstehend verlinkte Ansicht zeigt ein einfaches Screen zu einem ausgewählten Host (hier: ein Proxmox-Node aus unserem Testcluster). Die 6 zusammengestellten Graphen lassen sich bei Bedarf über den integrierten Editor in der Zabbix-Weboberfläche anpassen oder erweitern.
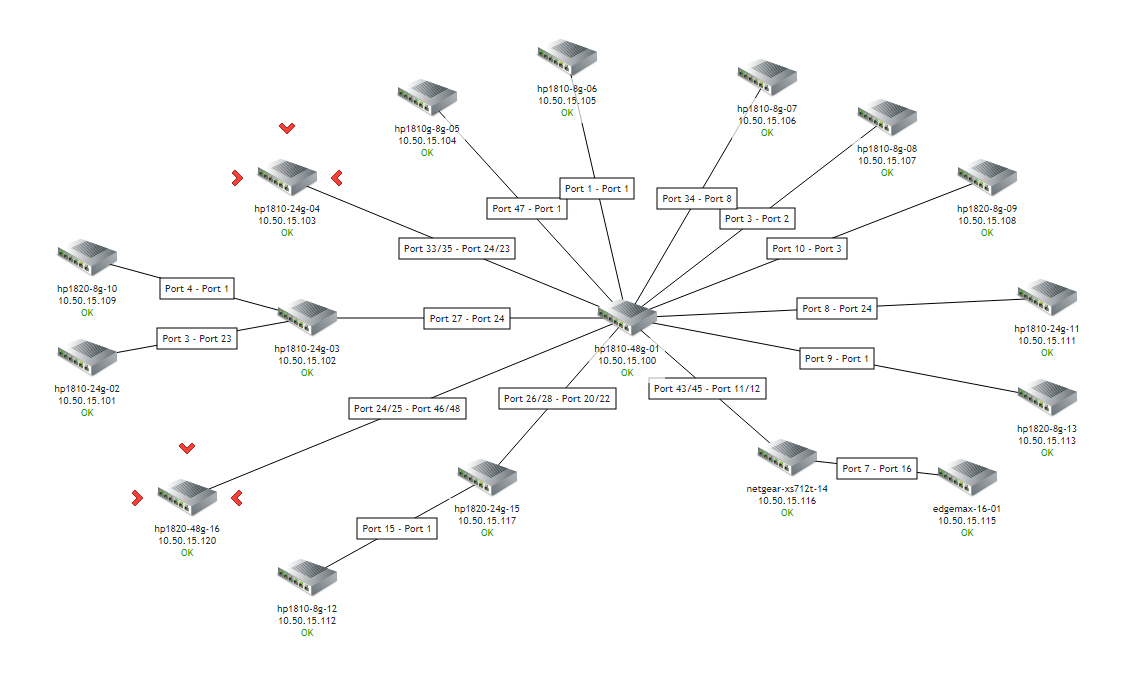
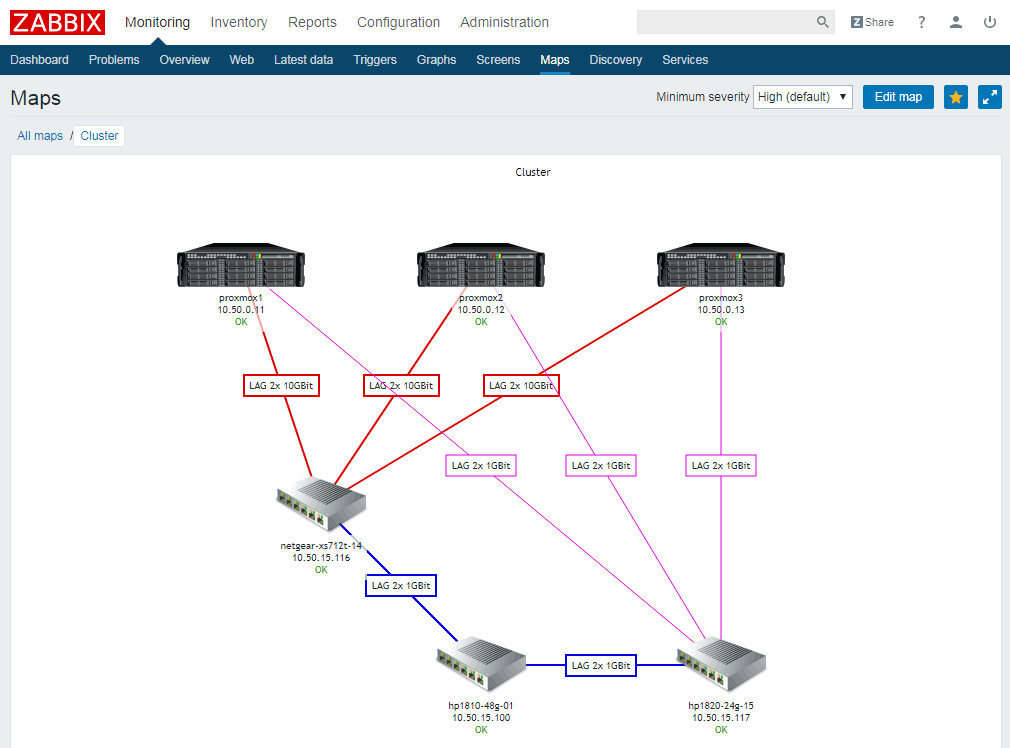
Eine grafische Darstellung mit freieren Gestaltungsmöglichkeiten bieten Maps. Diese können beispielsweise zur Erstellung von Topologieansichten genutzt werden, wie im nachfolgenden Screenshot zu sehen ist. Die Map wurde einfach über den Web-Editor zusammengeklickt und zeigt das Vernetzungsschema unseres Proxmox Testclusters. Die unter den Geräten kleinen, grünen OK-Symbole spiegeln übrigens den aktuellen Zustand der Monitoring-Überwachung wider. Im Fall einer Störung würde das entsprechende Gerät optisch hervorgehoben. Map-Elemente können darüber hinaus angeklickt werden, wodurch sich Informationen zum jeweiligen Gerät oder Dashboard-Ansichten aufrufen lassen.
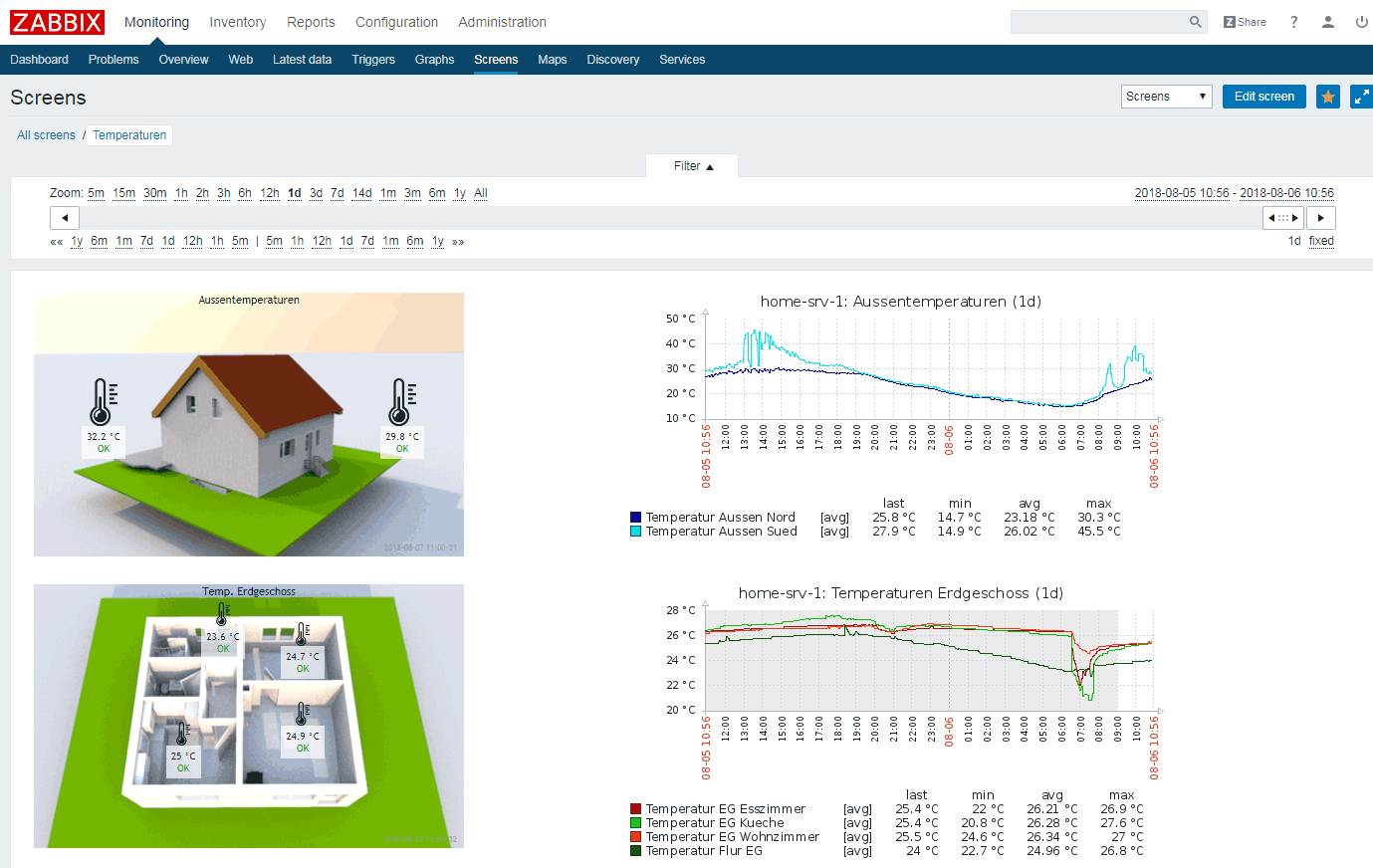
Screens in Zabbix erlauben es andererseits Maps als Gestaltungselemente einzubinden. Die nachstehend verlinkte Ansicht zeigt eine Zweckentfremdung von Zabbix zur Visualisierung von Temperaturen und deren Verläufen. Auf der linken Seite zeigen die Map-Darstellungen die aktuellen Temperaturen im symbolisierten Gebäude an und rechts daneben die Temperaturverläufe in Form von Graphen für den ausgewählten Zeitraum.
Wem die durchaus mächtige Weboberfläche von Zabbix mit ihrer Darstellung zu altbacken erscheint, möchte ich auf die oben erwähnte, optionale Grafana-Einbindung vertrösten. Als kleinen Vorgeschmack zeigen die beiden nachstehenden Abbildungen Auszüge eines Grafana-Dashboards. Das Dashboard visualisiert eine Menge Detailwerte unseres Proxmox Testclusters – direkt abgefragt aus Zabbix über die vorhandene Schnittstelle und optisch schön aufbereitet sowie interaktiv bedienbar, wie man es von Grafana gewohnt ist.
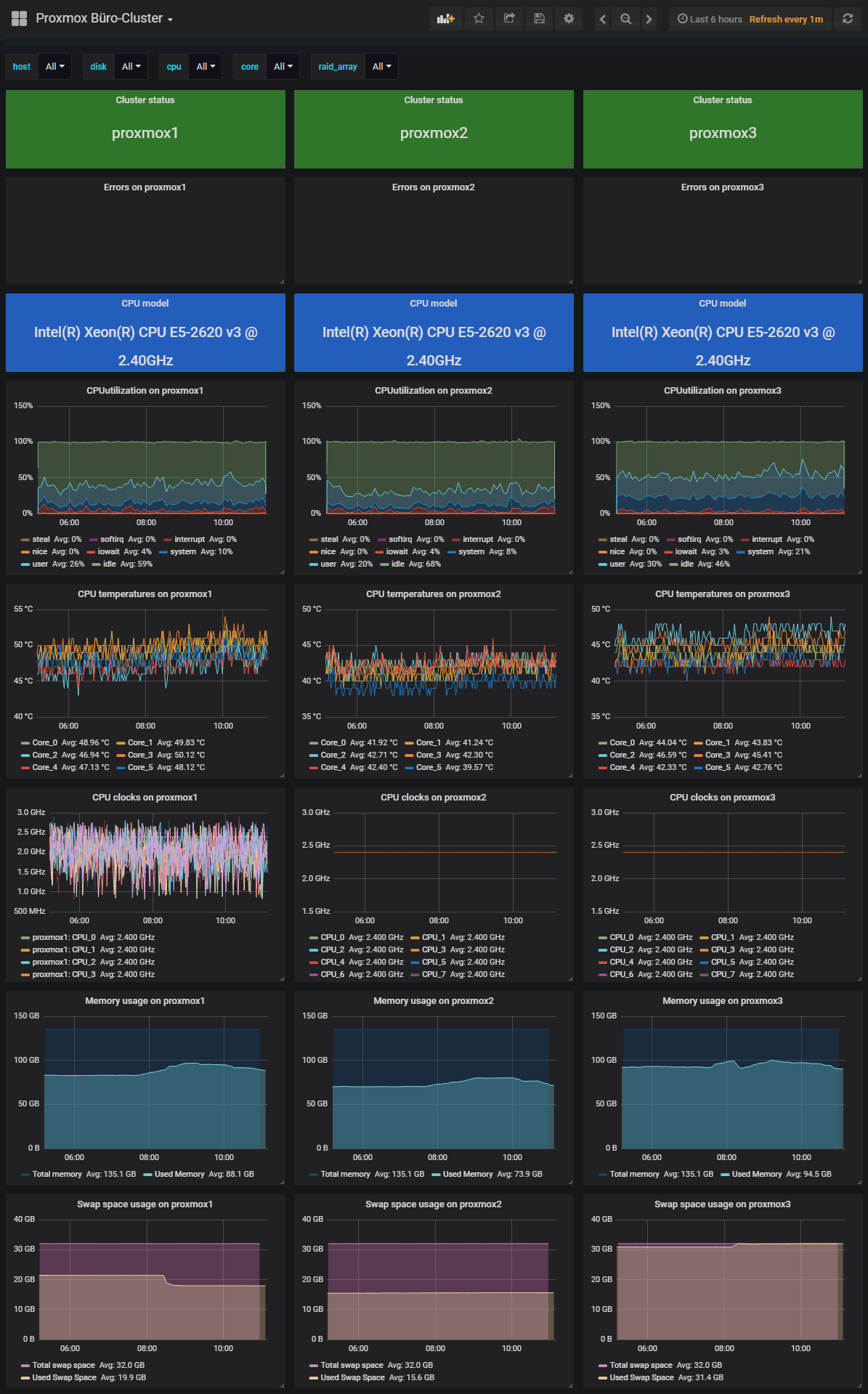
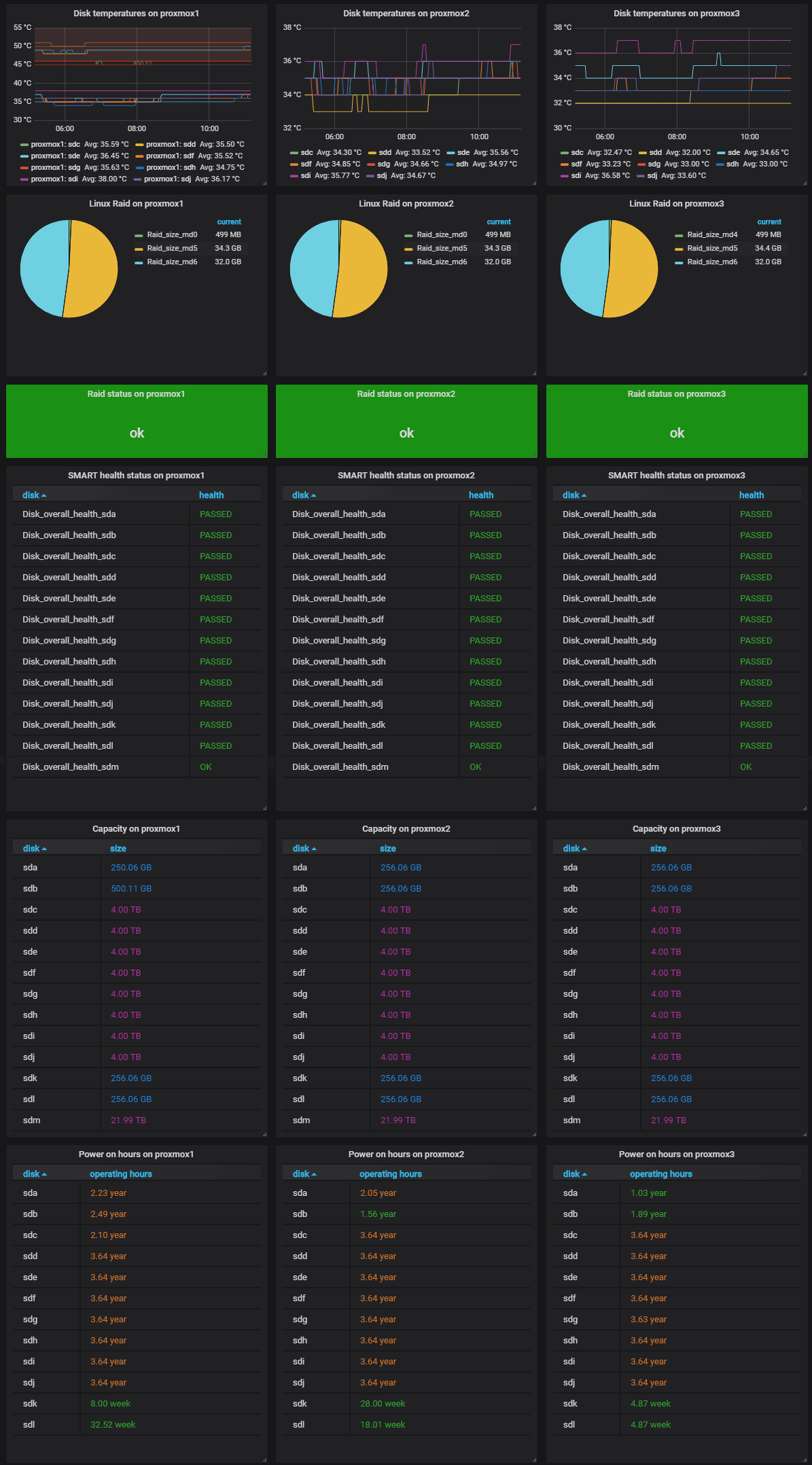
Beispiel 2: Auslesen von Festplattentemperaturen
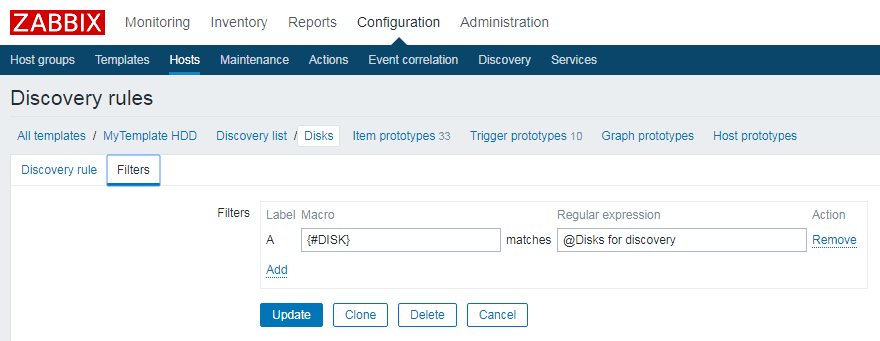
In diesem Beispiel möchte ich den oben zitierten Fall für die Ermittlung von Festplatten-Temperaturen aufgreifen. In Zabbix lässt sich dies ideal durch Erstellung eines passenden Templates lösen. Das Template soll universell für Linux-Server einsetzbar sein und die Temperatur aller im Gerät vorhandenen Festplatten automatisch erfassen. Da die Anzahl der Festplatten abhängig vom jeweiligen Gerät ist, muss man im Template eine Erkennungsroutine vorsehen – in Zabbix als „Discovery rule“ bezeichnet. Die nachstehenden Screenshots zeigt die Definition dieser Regel über die Zabbix-Weboberfläche.

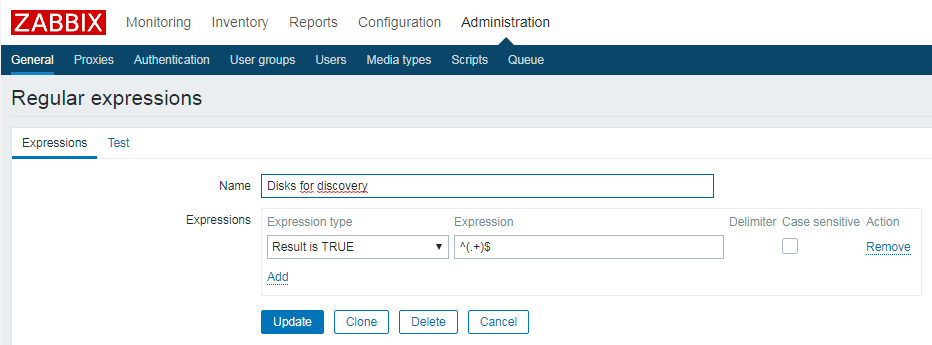
Der im zweiten Screenshot referenzierte reguläre Ausdruck ermöglicht es die eingelesenen Werte bei Bedarf zu parsen. In unserem Fall ist dies nicht erforderlich, so dass wir nur sicherstellen möchten, dass die Festplattenerkennung echte Devices liefert und Nullstrings herausgefiltert werden. Die nachstehende Abbildung zeigt die Definition des zugehörigen regulären Ausdrucks, der global in den Administrationseinstellungen hinterlegt wird.
Nun muss man noch dafür sorgen, dass Zabbix den im ersten Screenshot referenzierten Key (namens custom.hdd.disks) auslesen kann. Wie die Benennung des Keys suggeriert, handelt es sich hierbei um einen selbst erstellten Eingabewert, der uns die tatsächlichen Festplatten in einem Linux-Server zurückliefern soll. Der Key muss vom jeweiligen Linux-Server zurückgeliefert werden, der unser Festplatten-Template bedienen soll. Als Schnittstelle dient auf dem Client ein installierter Zabbix-Agent (mit Einbindung im Zabbix-Server).
Zabbix-Agenten bieten die Möglichkeit eigene Keys zu definieren. In Linux-Installationen erfolgt dies in Konfigurationsdateien üblicherweise unter /etc/zabbix (meist /etc/zabbix/zabbix_agentd.conf.d oder /etc/zabbix/zabbix_agentd.d abhängig von der Include-Definition in zabbix_agentd.conf). Die Definition eigener Keys ist sehr simpel und beschränkt sich auf eine Zuordnung von Schlüsselwert zu einem Skript oder Kommadozeilenbefehl, womit der Datenwert bestimmt werden kann. In unserem Fall legen wir die Konfigurationsdatei hdd.conf an mit nachstehend abgebildetem Inhalt.

Die Konfigurationsdatei enthält neben dem bereits genannten Key (custom.hdd.disks) in Zeile 2 eine weitere Schlüsselkonfiguration (custom.hdd.temperature[*]), über die im späteren Schritt die Festplattentemperaturen ausgelesen werden. Da dies für eine beliebige Anzahl Festplatten möglich sein soll, ist der zweite Schlüssel als Array definiert, der als Übergabeparameter die Festplattenbezeichnung (z.B. sda, sdb, …) übergeben bekommt. Die Ermittlung genau der im System vorhandenen Festplattenbezeichnung wiederum ist die Aufgabe unseres ersten Keys, den wir oben definiert haben.
An dieser Stelle möchte ich nicht in Linux-spezifische Internas abdriften, mit denen man vorhandene Geräte und Festplattentemperaturen per Kommandozeilenutility ermittelt. Entscheidend im zuletzt dargestellten Screenshot ist das Mapping von selbst erstellten Keys zu einem Kommandozeilenbefehl (hier dem Skript /usr/share/zabbix-agent/scripts/hdd), das uns die gewünschten Werte zurückliefert. Interessant ist noch die Ausgabe des ersten Schlüssels (custom.hdd.disks), der den Discovery-Mechanismus unseres oben definierten Templates bedient. Das Template erwartet hier eine Rückgabe in Form eines JSON-Arrays. Wie dies aussehen kann, zeigt die folgende Abbildung am Beispiel eines unserer Proxmox-Nodes.

In diesem Fall erkennt das Template 13 Festplatten mit den Linux-typischen Device-Bezeichnungen sda, sdb, …, sdm. Passend zur oben abgebildeten Discovery rule erfolgt die Zuordnung zum Makro-Bezeichner {#DISK} (vgl. mit Abbildung 2 im Beispiel).
Nun kann im nächsten Schritt unterhalb der Discovery rule ein dynamisches Item erstellt werden, das die tatsächlichen Temperaturwerte der Festplatten erfasst. Die entsprechende Item-Definition zeigt die nachfolgende Abbildung. Relevant ist hier v.a. die Festlegung des Keys, dessen Definition bereits oben als zweiter Schlüssel in unserer Konfigurationsdatei zu sehen war. Die dargestellte Festlegung als custom.hdd.temperature[{#DISK}] sorgt dafür, dass das Item pro vorgefundenem Festplatten-Device erstellt wird.
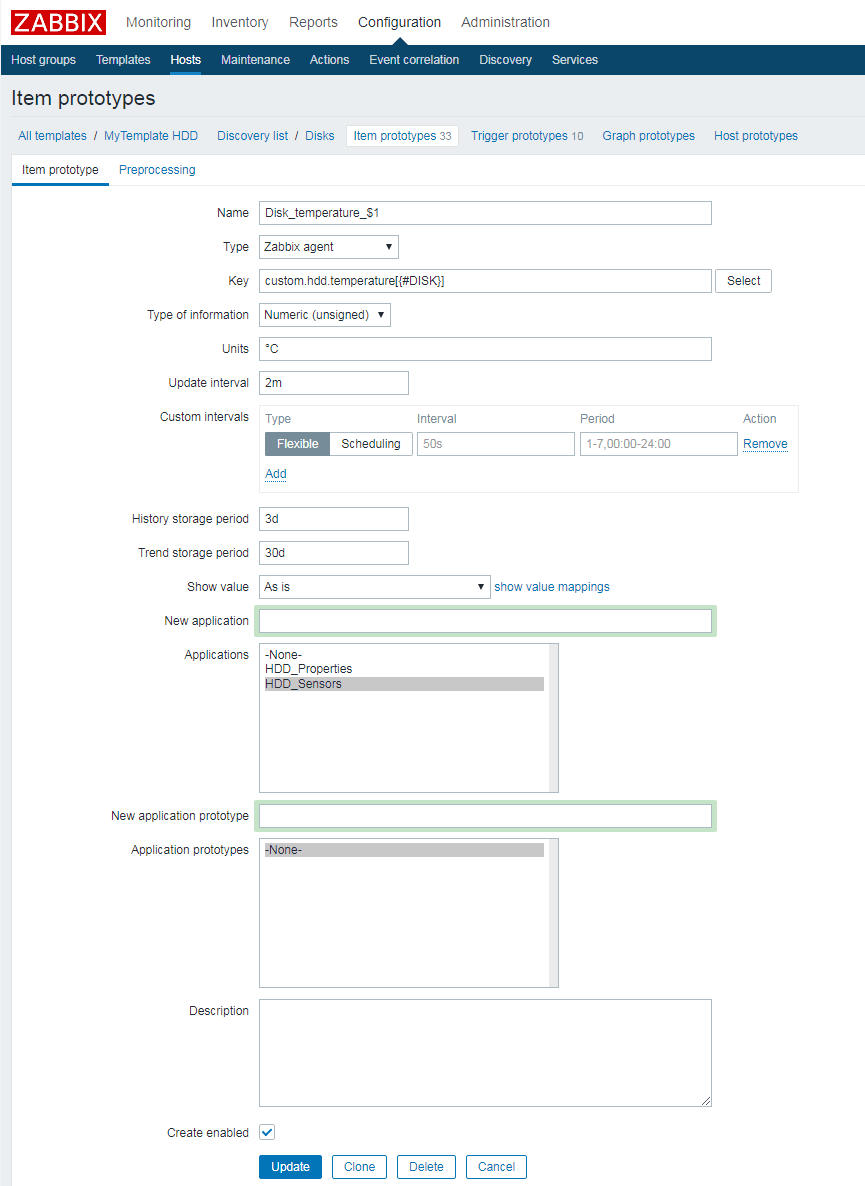
Auf den ersten Blick mag dieses Beispiel etwas komplex erscheinen. Wer jedoch einmal die Template-Erstellung in Zabbix nachvollzogen hat, kann die benötigten Schritte anschließend schnell anwenden und verfügt damit über ein mächtiges Werkzeug, mit dem sich beliebige Messdaten im Monitoring erfassen lassen. Durch die dynamische Definition von Items lässt sich die Datenerhebung darüber hinaus flexibel und elegant für unterschiedliche Umgebungen anwenden.
Beispiel 3: Monitoring der virtuellen Maschinen in einem Proxmox-Cluster
Im letzten Beispiel möchte ich einen komplexen Anwendungsfall vorstellen und die Möglichkeiten demonstrieren, diesen durch Monitoring mit Zabbix zu erfassen.
Ausgangspunkt ist der zuvor schon mehrfach genannte Proxmox-Cluster. Proxmox VE ist eine Open Source Virtualisierungslösung auf Basis von Linux, die insbesondere Virtualisierung mittels QEMU/KVM unterstützt. Damit lassen sich virtuelle Maschinen mit unterschiedlichen Gastsystemen betreiben. Im Clusterverbund können diese VMs jeder Zeit per Live-Migration zwischen den Cluster-Nodes verschoben werden. Darüber hinaus unterstützt Proxmox VE von Haus aus Hochverfügbarkeit und die Replikation von virtuellen Maschinen. Neben anderen Anwendungsfällen setzen wir für unsere eigene, interne Serverlandschaft mehrere Proxmox-Cluster ein. Dieser Praxiserfahrung verdanken wir etliche Kenntnisse sowie Konfrontationen mit Problemen, wie sie im Alltag auftreten. Letztere sind dabei zum Teil allgemeiner Natur wie man sie auch in anderen Virtualisierungsumgebungen mit ähnlichem Systemaufbau vorfindet.
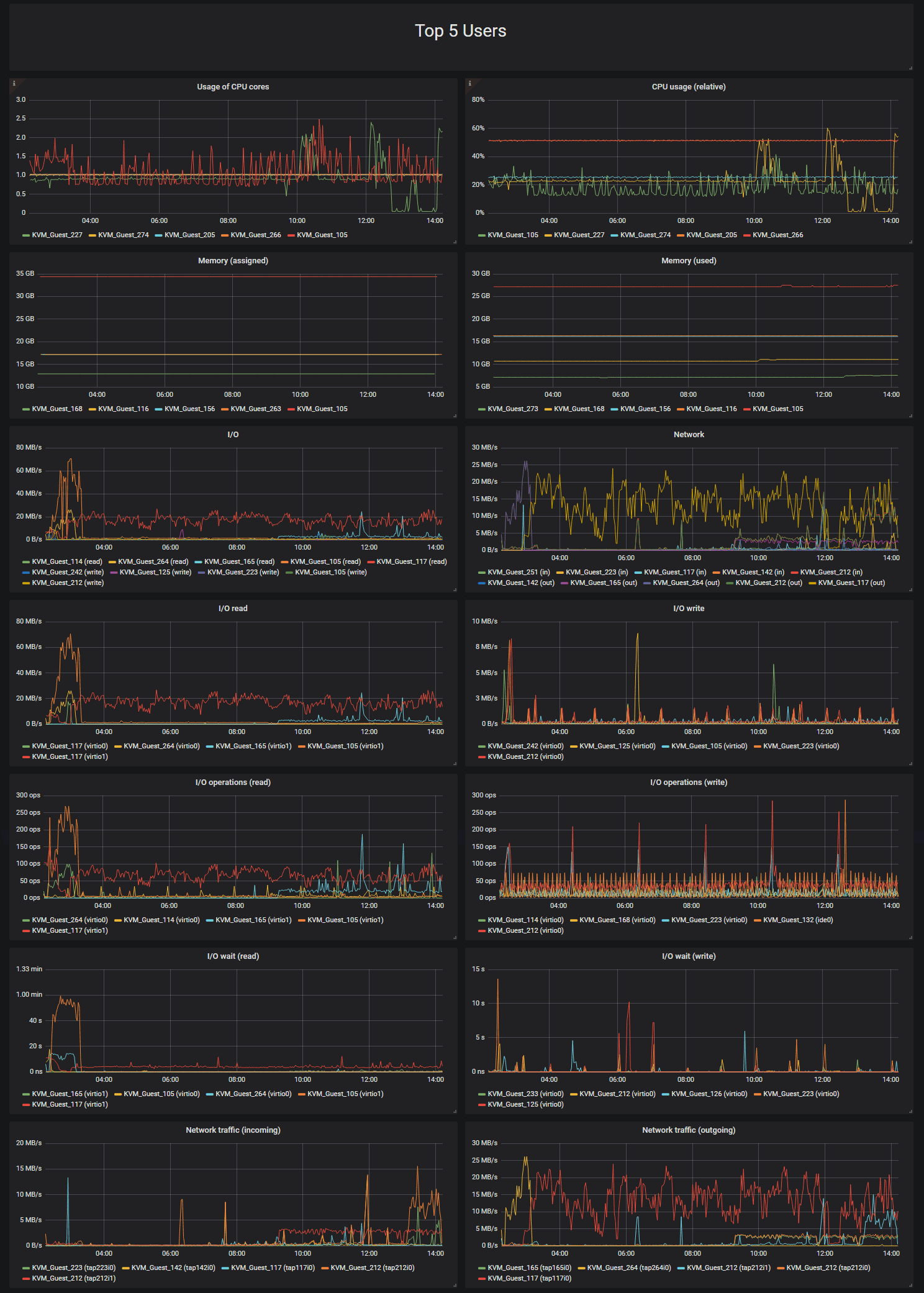
Ein ordentlich dimensionierter Virtualisierungscluster ist ein feines Werkzeug für den Betrieb einer Serverlandschaft. Da Hardware nur noch auf Seite der Virtualisierungsplattform vorgehalten wird, ist die Bereitstellung von Anwendungsservern im Idealfall mit wenigen Mausklicks bewerkstelligt. Problematisch wird es hingegen, wenn die Virtualisierungsumgebung an ihre Grenzen stößt und die Performance der gehosteten VMs spürbar in die Knie geht. Unzufriedene Anwender einerseits und fieberhafte Ursachensuche andererseits werden dann schnell zur Herausforderung für die IT-Administration. Falls keine offensichtlichen Defekte Auslöser für den plötzlichen Performance-Einbruch sind, kann die Ursachenforschung zur Nadelsuche im Heuhaufen werden. Aussagekräftige Daten aus dem Monitoring können jetzt den entscheidenden Vorteil bringen. Ohne Fehler auf Seite der Virtualisierungsplattform gilt es die gehosteten VMs unter die Lupe zu nehmen und darunter Perfomance-Fresser zu identifizieren. Ideal wäre es eine Darstellung der ressourcenintensivsten VMs zu bekommen, die als wahrscheinliche Verursacher für den Performance-Engpass in Frage kommen. Ausschlaggebend sind in erster Linie beanspruchte Ressourcen wie CPU-Leistung, RAM-Anforderung, v.a. aber Storage-Beanspruchung (Festplatten Lese-/Schreibraten und IOPS) und Netzwerktransfers.
Mit einem ordentlichen Monitoring lassen sich die Daten fortlaufend ermitteln, müssen jedoch für jede gehostete VM erhoben werden. Einen Zusatzaufwand machen in der Regel heterogene Umgebungen mit unterschiedlichen Gastsystemen. Auch gilt es das Monitoring ständig an die im Wechsel begriffenen Serverlandschaft anzupassen, also neu hinzugekommene VMs aufzunehmen und nicht mehr existente VMs zu entfernen. Ideal wäre es diesen Prozess zu automatisieren, so dass die Datenerhebung im Monitoring komplett ohne menschlichen Eingriff auskommt. Für eine Realisierung müssen daher 2 Anforderungen umgesetzt werden:
- Die automatische Aufnahme und Pflege der virtuellen Maschinen in das Monitoring
- Die Erfassung der Ressourcen-Nutzung (CPU-Auslastung, RAM-Belegung, Festplatten-Operationen und Netzwerk-Bandbreite) je VM
Bei Punkt b) gilt es zu beachten, dass VMs mit unterschiedlichen Gastsystemen zum Einsatz kommen. Bei einer Ermittlung der Ressourcen-Nutzung innerhalb der VMs würden daher Monitoring-Clients für unterschiedliche Betriebssysteme benötigt. Für „exotische“ VMs wie gehärtete Software-Appliances (z.B. Firewalls, Netzwerkmanagement oder WLAN-Controller) wird dies zudem unmöglich sein. Sehr viel eleganter und universell nutzbar ist es daher die Ressourcen-Nutzung der einzelnen VMs am Virtualisierungs-Host zu erfassen. Proxmox VE ermöglicht dies über das Kommandozeilen-Utility qm.
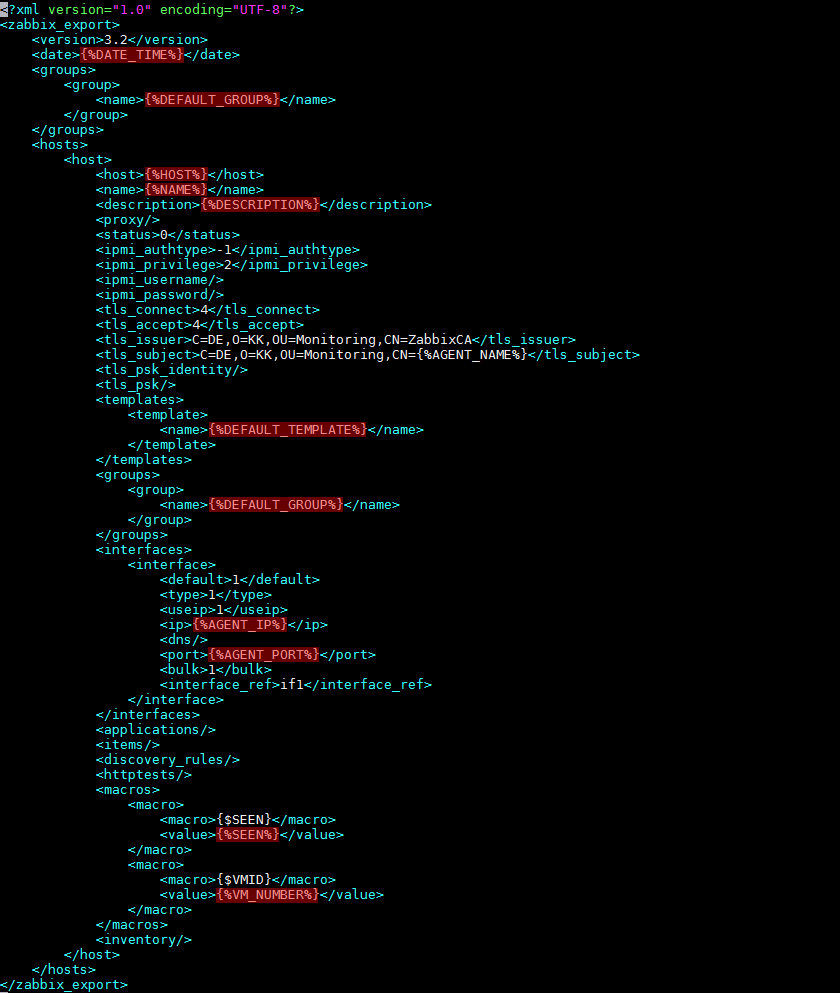
Für die in Punkt a) geforderte automatisierte Aufnahme der VMs in Monitoring ist ein Skripting der Zabbix-API erforderlich. Sehr gut eignet sich hierfür das zuvor genannte Python-Skript Zabbix-CLI. Die aktuell vorhandenen VMs im Cluster kann man bei Proxmox VE einfach anhand ihrer Konfigurationsdateien (im Verzeichnis /etc/pve/qemu-server) ermitteln. Für die Aufnahme der VMs in das Zabbix-Monitoring erwartet Zabbix-CLI pro VM eine XML-Datei mit der Host-Konfiguration. Die nachstehende Abbildung zeigt eine entsprechende Vorlage, bei der die rot eingefärbten Variablen durch die Merkmale der jeweiligen VM auszufüllen sind.
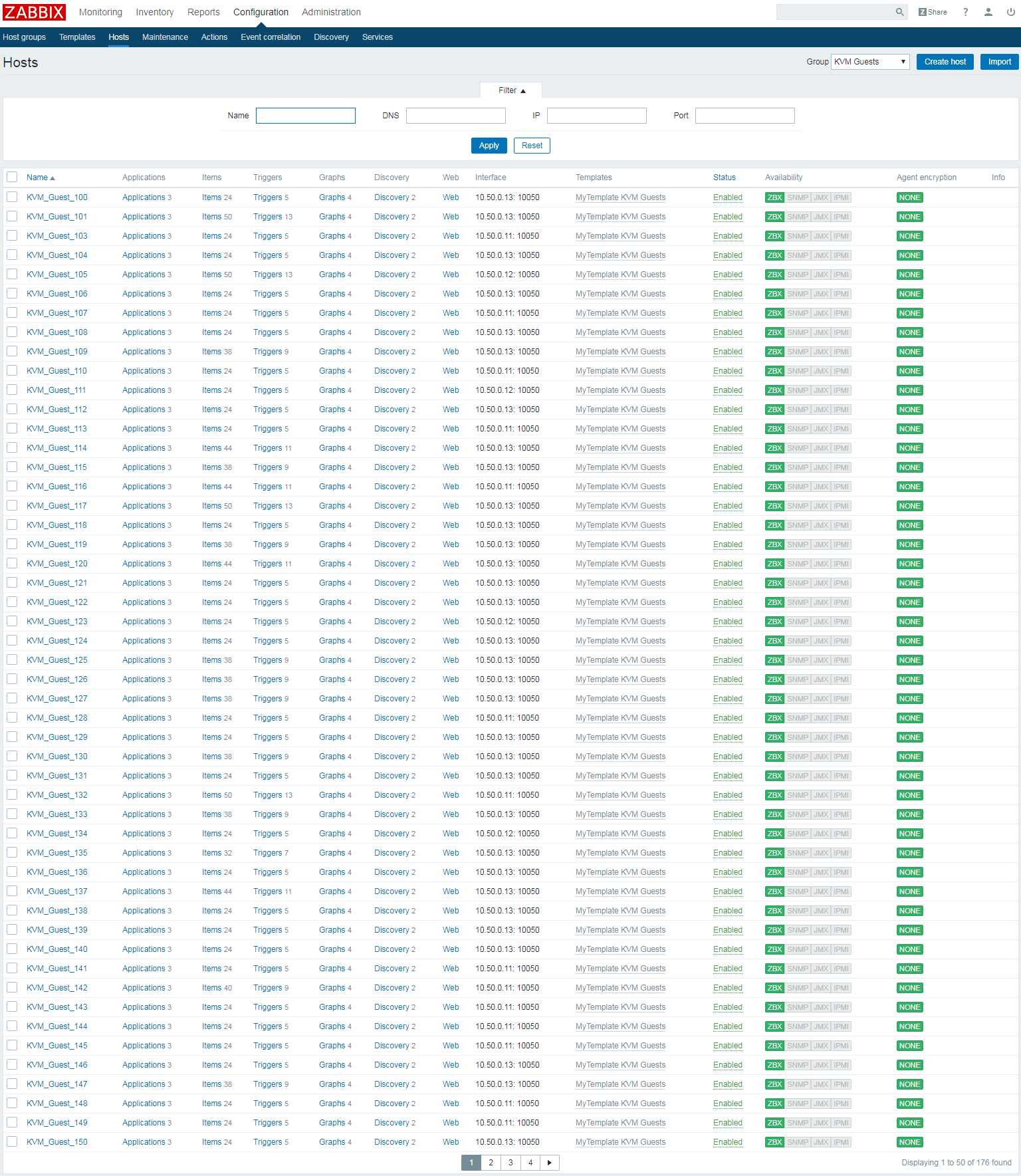
Nach erfolgreichem Import aller vorhandenen VMs stehen diese im Zabbix-Monitoring zur Verfügung wie im folgenden Screenshot zu erkennen ist. Zur fortlaufenden Pflege des Host-Bestands im Monitoring sollte der automatische Import neben der Aufnahme neuer VMs auch das Entfernen nicht mehr existenter VMs berücksichtigen.
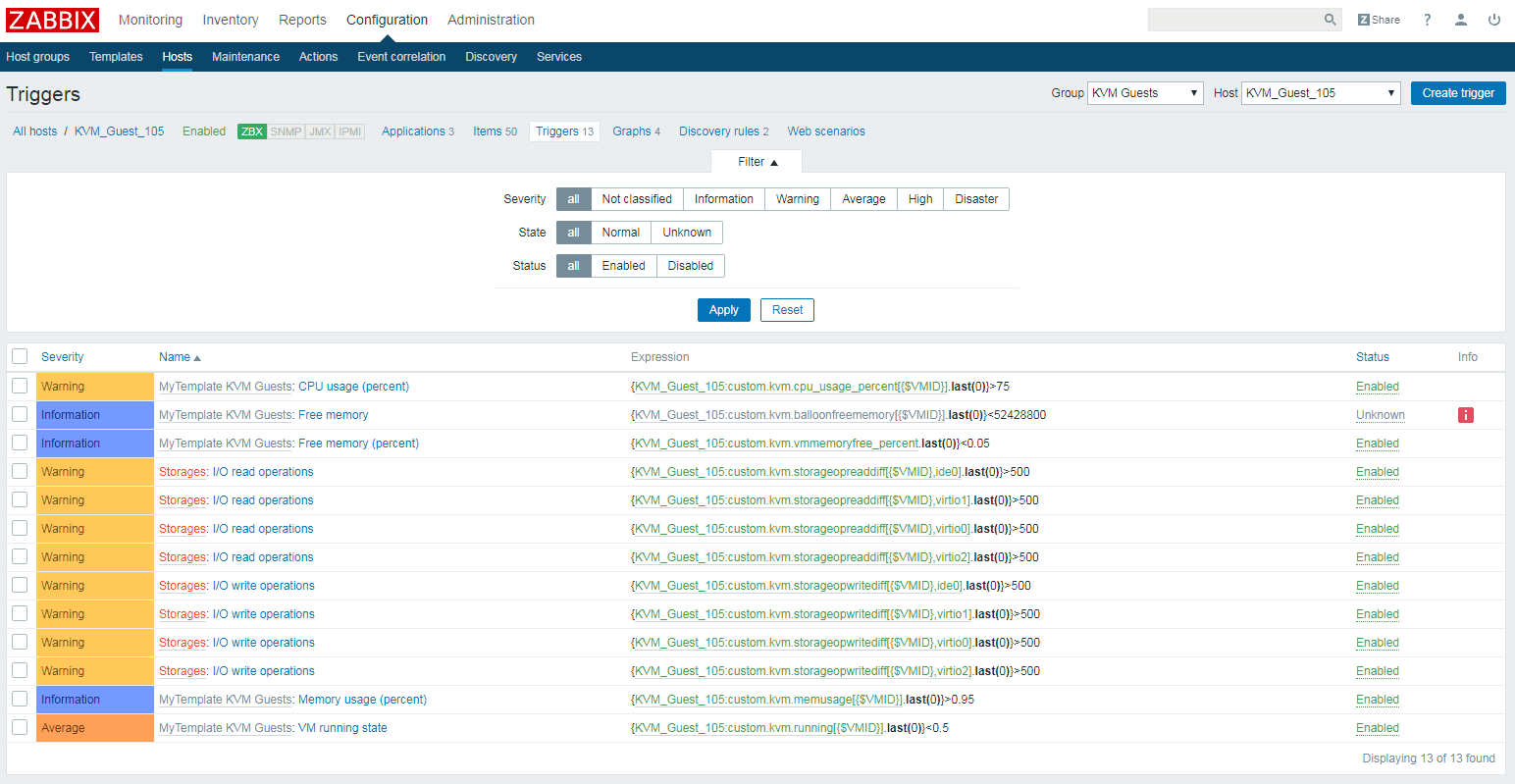
Nach der Aufnahme in das Monitoring beginnt Zabbix sofort mit der fortlaufenden Erfassung der Ressourcen-Nutzung durch jede VM. Die nachstehende Abbildung zeigt für eine ausgewählte VM beispielhaft die Trigger (Alarmierungen), die bei Überschreitung der festgelegten Grenzen (z.B. Anzahl von IOPS) zu Warnungen durch das Monitoring führen.
Für das eingangs beschriebene Szenario von Performance-Engpässen im Virtualisierungs-Cluster liefert das Monitoring damit wertvolle Daten und identifiziert VMs mit hohem Ressourcenverbrauch. Mit dem abschließend abgebildeten Dashboard in Grafana lassen sich beispielsweise die 5 ressourcenintensivsten VMs in jeder Kategorie aufdecken. Dies gibt dem Administrator die Möglichkeit ausufernde VMs einzuschränken und schleichende Fehlentwicklungen aufzudecken.
Ich hoffe mit den im Beitrag vorgestellten Beispielen einen Einblick in die vielfältigen Möglichkeiten zur Datenüberwachung mit Zabbix gegeben zu haben.
Die nachstehende Tabellte listet abschließend einige Links zur vertieftem Lektüre.
| Link | URL |
| Zabbix Homepage | https://www.zabbix.com/ |
| Zabbix Dokumentation | https://www.zabbix.com/documentation/3.4/start |
| Zabbix Wiki | https://www.zabbix.org/wiki/Main_Page |
| Zabbix Templates | https://share.zabbix.com/ |
| Zabbix-CLI | https://github.com/usit-gd/zabbix-cli/blob/master/docs/manual.rst |
| Grafana | https://grafana.com/ |
| Zabbix-Plugin | https://grafana.com/plugins/alexanderzobnin-zabbix-app |
Die Namensnennung von Firmen oder Markennamen dient lediglich der redaktionellen Verwendung, zur Abgrenzung und zur Kenntlichmachung der Kompatibilität im Rahmen des jeweiligen Geschäftsumfanges. Die Zeichen, Begriffe und Namen sind gegebenenfalls geschützte Marken- und Warenzeichen der jeweiligen Rechteinhaber. Die angebotene Ware ist zu vielen Produkten namhafter Marken kompatibel, es handelt sich aber keinesfalls um Produkte der betreffenden Firmen und Marken! Autor: Armin Krauß – K&K Software AG
