Inhaltsverzeichnis
1.3 Schnittstellen und Zugriffswege
2.2 VLANs und Netzwerkanbindung
2.3 Node-Konfiguration, Dienste und IP-Adressen
2.4 Storage-Zusammensetzung: Festplatten und OSDs
1. Grundkonzept
1.1 Merkmale
Bei Ceph handelt es sich um ein verteiltes Dateisystem für Hochverfügbarkeit, mit dem sich große und sehr große Storages realisieren lassen.
Zentrale Merkmale von Ceph sind:
- Robustes Design gegen Ausfallsicherheit (kein Single Point of Failure) durch die Verteilung auf mehrere Nodes
- Hohe Skalierbarkeit sowohl was die Storage-Kapazität als auch die Erweiterbarkeit der beteiligten Nodes betrifft
- Hohe Flexibilität
- Software basierende Lösung (keine starren Raid-Systeme erwünscht)
- Selbst-verwaltend und mit eigenständigen Mechanismen zur Fehlerbehebung
- Open Source
Als verteiltes Dateisystem erstreckt sich ein Ceph-Storage über mehrere (bis viele) Einzelrechner – sogenannte Nodes –, die im Verbund zusammenarbeiten. Dieser Verbund wird auch als Ceph-Cluster bezeichnet.
1.2 Aufbau und Architektur
In einem Ceph-Cluster gibt es unterschiedliche Rollen (Aufgabenbereiche), die von den einzelnen Nodes erledigt werden.
Monitore und Manager
Monitore verwalten sie sogenannte Cluster Map und erfüllen eine organisatorische Aufgabe im fortlaufenden Betrieb. Seit Version 12 des Ceph-Dateisystems werden daneben noch Manager benötigt als Schnittstelle für externe Zugriffe und für zusätzliche Monitoring-Aufgaben.
Zum Betrieb eines lauffähigen Clusters wird immer mindestens 1 funktionierender Monitor sowie 1 Manager benötigt. Um einen Single Point of Failure zu vermeiden, sollte man in der Praxis mehrere Monitore und Manager vorhalten. Dabei sollte man auf eine ungerade Anzahl setzen, damit der Cluster im Fall eines internen Konflikts entscheidungsfähig ist.
Bei einem Minimal-Cluster bestehend aus 3 Nodes macht es daher Sinn, auf allen 3 Nodes Monitore und Manager bereitzustellen.
Object Storage Node (OSD)
Object Storage Nodes stellen die eigentliche Speicherkomponente im Ceph-Storage dar. Bei einem OSD handelt es sich typischerweise um eine (einzelne) Festplatte in einem Ceph Node. Der Ceph-Storage setzt sich also insgesamt aus vielen OSDs zusammen bzw. die Daten in einem Ceph-Dateisystem verteilen sich auf die vielen verfügbaren OSDs.
Jedes OSD verfügt über seinen eigenen Dienst (OSD Daemon), der die Anfragen und Zugriffe auf die dahinterliegende Speichereinheit verwaltet.
Ursprünglich verwendete Ceph zur Datenspeicherung auf den OSDs bewährte Linux Dateisysteme (XFS, Ext4, btrfs). Neben dem endgültigen Speicherplatz auf einem Datenträger wurde außerdem ein sogenanntes Journal angelegt, das als Zwischenspeicher für alle eingehenden Schreibzugriffe zum Einsatz kam.
Seit Version 12 des Ceph-Dateisystems werden OSDs mittlerweile standardmäßig im sogenannten BlueStore-Format erzeugt. Hierbei handelt es sich um ein natives Dateisystem von Ceph, das mit einigen Nachteilen des Vorgängerkonzepts aufräumt, u.a. das zuvor separate Journal in den Datenspeicher integriert und dadurch insgesamt für einen spürbaren Performancegewinn sorgt.
Die nachstehende Abbildung zeigt schematisch den Aufbau eines Ceph-Storages:
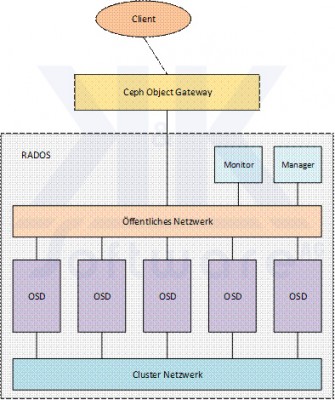
RADOS steht für Reliable Autonomic Distributed Object Store und stellt innerhalb von Ceph die Schicht zur Datenspeicherung dar.
1.3 Schnittstellen und Zugriffswege
Ceph-Storages können auf unterschiedliche Art und Weise genutzt werden. Hierfür stellt Ceph mehrere Schnittstellen zur Verfügung, die zum Teil über spezielle Anpassungen für den jeweiligen Einsatzzweck verfügen. Durch die zunehmende Verbreitung und Beliebtheit von Ceph als zuverlässigen und kostengünstigen Storage entstehen fortlaufend neue Szenarien und werden seitens Ceph neue Möglichkeiten und Verbesserungen vorangetrieben.
Die grundsätzlichen Zugriffskonzepte zeigt die nachstehende Abbildung:
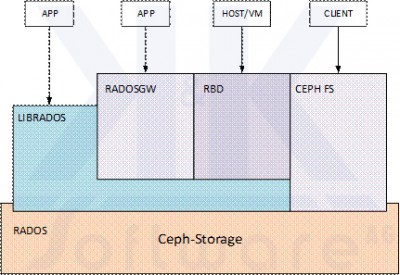
RADOSGW ist ein Web Service Gateway mit RESTful API, der eine Anbindung zu Amazon S3 und OpenStack ermöglicht.
RBD (RADOS Block Device) stellt Speicherkapazität auf dem Ceph-Storage in Form von Block Devices zur Verfügung. Damit lassen sich beispielsweise virtuelle Festplattenimages im Ceph-Storage ablegen, die zum Betrieb von VMs genutzt werden.
CephFS bietet ein POSIX konformes Dateisystem auf dem Ceph-Cluster.
LIBRADOS stellt eine native Schnittstelle zum direkten Zugriff auf RADOS dar, über die Applikationen Zugang zum verteilten Storage bekommen.
1.4 iSCSI-Schnittstelle
Die zuvor beschriebenen Schnittstellen stellen die grundsätzlichen Zugangswege zum Ceph-Storage dar. Weiterer Zugriffsmöglichkeiten lassen sich auf Basis der o.g. Schnittstellen und unter Zuhilfenahme zusätzlicher Applikationen und Dienste realisieren.
Für die in klassischen Storagekonzepten beliebte iSCSI-Schnittstelle gibt es unter Linux mehrere Umsetzungen. Eine gute Ceph-Integration bietet das Linux SCSItargetframework (TGT).
Den schematischen Aufbau einer Ceph/iSCSI-Anbindung zeigt die nachstehende Abbildung:
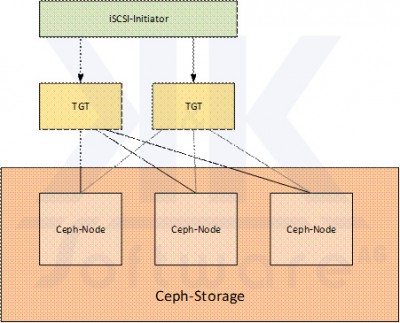
Durch Bereitstellen des TGT iSCSI-Dienstes auf mehreren Nodes erhält man eine hochverfügbare iSCSI-Anbindung. Clientseitig erfordert dies eine Konfiguration mit Multipath.
2. Realisierung
Im Abschnitt 2: Realisierung stellen wir nun am Beispiel eines kleinen Ceph-Clusters Konzeptionierung und Aufbau eines Ceph-Storages mit iSCSI-Anbindung vor. Letztere ermöglicht die Nutzung des Storages auch durch fremde Systeme, wie z.B. eine VMware Umgebung. Dabei befassen wir uns zunächst mit dem Grundaufbau und Netzwerkanforderungen und anschließend der Konfiguration von Festplatten und OSDs.
Das hier vorgestellte Beispiel demonstriert einen kleinen Anwendungsfall und stellt daher keinen allgemeinen Ratgeber für den Aufbau eines Ceph-Storages dar. Es zeigt aber die grundsätzlichen Komponenten und Aspekte, die zur Planung eines eigenen Einsatzes von Ceph nötig sind.
2.1 Ceph-Cluster
Der Ceph-Cluster besteht initial aus 3 Nodes, die gemeinsam den Ceph-Storage aufspannen wie in der nachstehenden Abbildung veranschaulicht:
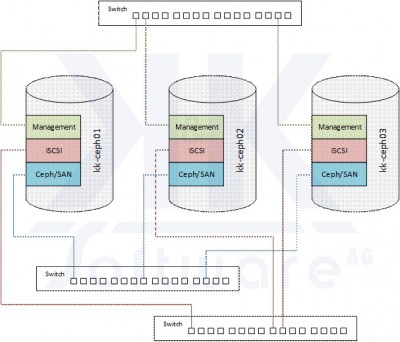
Wie dargestellt sind die Nodes untereinander über unterschiedliche Netzwerke verbunden:
- Das Management-Netz dient zum administrativen Zugriff auf die Nodes sowie zu Überwachung und Monitoring
- Die ISCSI-Schnittstellen sind über eine eigenständige Netzwerkverbindung nach außen geführt
- Das Ceph/SAN-Netzwerk schließlich steht exklusiv zur Datensynchronisierung des Ceph-Storage (internes Netzwerk) zur Verfügung
Zum Schutz gegen äußere Einflüsse sind die 3 Ceph-Nodes in unterschiedlichen Rechenzentren bzw. Gebäudeteilen untergebracht, um den Betrieb auch im Fall von Störungen und Ausfällen einzelner Einrichtungen fortführen zu können.
2.2 VLANs und Netzwerkanbindung
Die zuvor genannten Netzwerkverbindungen zwischen den Nodes sind innerhalb der Netzwerk-Infrastruktur wie nachstehend realisiert:
| Typ | VLAN | IP-Bereich | Geschwindigkeit |
| Management | 101 | 10.1.1.0 / 255.255.255.0 | 1 GBit/s |
| iSCSI | 12 | 10.10.12.0 / 255.255.255.0 | 10 GBit/s (Standby: 1 GBit/s) |
| Ceph/SAN | 11 | 10.10.11.0 / 255.255.255.0 | 10 GBit/s (Standby: 1 GBit/s) |
Jeder Node verfügt aus Gründen der Redundanz jeweils über mehrfache Schnittstellen in die obenstehenden Netzwerke. Diese sind teilweise in Form von LAGs sowie als Standby-Schnittstellen (zum Failover-Betrieb) konfiguriert.
Im konkreten Beispiel verfügen die Ceph-Nodes über die nachstehende Schnittstellenkonfiguration:
| Schnittstelle | Bandbreite | VLAN | Verwendung |
| eno1 | 1 GBit/s | 101 | Management (LAG) |
| eno2 | 1 GBit/s | 101 | Management (LAG) |
| ens2f0 | 10 GBit/s | 12 | iSCSI (LAG) |
| ens2f1 | 10 GBit/s | 12 | iSCSI (LAG) |
| ens3f0 | 10 GBit/s | 11 | Ceph/SAN (LAG) |
| ens3f1 | 10 GBit/s | 11 | Ceph/SAN (LAG) |
| ens7f0 | 1 GBit/s | 11 | Ceph/SAN (LAG, Stby.) |
| ens7f1 | 1 GBit/s | 12 | iSCSI (LAG, Stby.) |
2.3 Node-Konfiguration, Dienste und IP-Adressen
Die oben vorgestellten 3 Ceph-Nodes sind alle nach identischem Schema aufgebaut und konfiguriert.
Wie nachstehend abgebildet erfüllen Sie jeweils die folgenden Aufgaben:
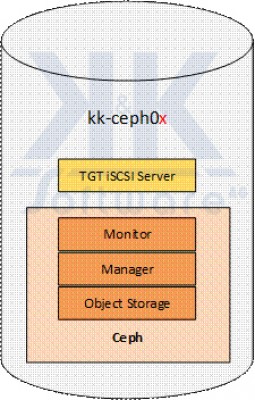
Jeder Ceph-Node verfügt jeweils über
- 1 Ceph-Monitor
- 1 Ceph-Manager
- Object Storage in Form mehrerer OSDs
Außerdem bietet jeder Node eine iSCSI-Schnittstelle zum Zugriff auf den Ceph-Storage.
Die IP-Adressen der Nodes in den unterschiedlichen Netzwerken sind in der nachstehenden Tabelle zusammengefasst:
| kk-ceph01 | kk-ceph02 | kk-ceph03 | |
| Management | 10.1.1.11 | 10.1.1.12 | 10.1.1.13 |
| iSCSI | 10.10.12.11 | 10.10.12.12 | 10.10.12.13 |
| Ceph/SAN | 10.10.11.11 | 10.10.11.12 | 10.10.11.13 |
2.4 Storage-Zusammensetzung: Festplatten und OSDs
Die Ceph-Nodes verfügen über identische Hardware. Die Festplatten-Bestückung und Organisation folgt jeweils dem nachstehend abgebildeten Schema: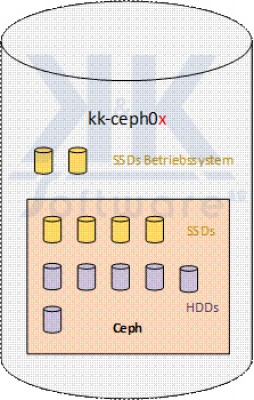
Das Betriebssystem nutzt 2 SSDs, die zu einem Raid-1 (Linux Software Raid) zusammengefasst sind.
Die restlichen SSDs (4 Stück) sowie konventionellen SAS-Festplatten (6 Stück) werden exklusiv als Ceph-Storage genutzt. D.h. jede dieser SSDs und SAS-Festplatten bildet ein OSD im Ceph-Storage.
Die genaue Zuordnung in einem Ceph-Node zeigt die nachstehende Tabelle:
| Device | Typ | Verwendung |
| /dev/sda | SAS-Festplatte | Ceph-Storage |
| /dev/sdb | SAS-Festplatte | Ceph-Storage |
| /dev/sdc | SAS-Festplatte | Ceph-Storage |
| /dev/sdd | SAS-Festplatte | Ceph-Storage |
| /dev/sde | SAS-Festplatte | Ceph-Storage |
| /dev/sdf | SAS-Festplatte | Ceph-Storage |
| /dev/sdg | SSD | Linux OS |
| /dev/sdh | SSD | Linux OS |
| /dev/sdi | SSD | Ceph-Cache |
| /dev/sdj | SSD | Ceph-Cache |
| /dev/sdk | SSD | Ceph-Cache |
| /dev/sdl | SSD | Ceph-Cache |
Bei der Auswahl der SSDs wurde außerdem zwischen dem Einsatz als Betriebssystem-Datenträger und der Verwendung als Ceph OSD (Ceph-Cache) unterschieden. An letztere sind deutlich höhere Anforderungen hinsichtlich Geschwindigkeit, Durchsatz (insbesondere IOPS, d.h. Input/Output Operations Per Second) und Haltbarkeit zu stellen.
2.5 Storage-Pools
Wie zuvor dargestellt, setzt sich der Ceph-Storage aus den OSDs der 3 Ceph-Nodes zusammen. Die OSDs sind dabei abhängig von ihrem Typ (SSD oder konventionelle Festplatte, nachstehend als HDD bezeichnet) zu unterschiedlichen Gruppen zusammengefasst. Dies hat den Sinn, schnelle und speichermäßig beschränkte SSDs sowie HDDs mit höherer Speicherkapazität aber langsamer Zugriffszeit als separate Storages mit unterschiedlichem Anwendungsprofil einsetzen zu können.
Die OSD-Organisation der 3 Ceph-Nodes und ihre Zuordnung zu Storage-Pools zeigt die nachstehende Abbildung:
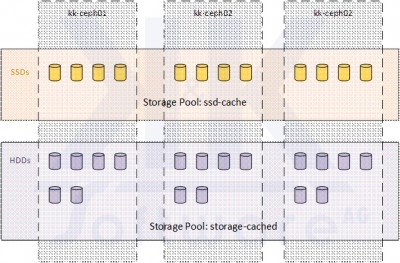
Im Storage-Pool ssd-cache sind alle Ceph zugeordneten SSDs zusammengefasst. Dieser Storage-Pool ist nicht zur direkten Nutzung vorgesehen. Er ist vielmehr transparent dem nachfolgenden Pool storage_cached vorgeschaltet und wirkt als schneller Zwischenspeicher (Cache), um Schreibzugriffe, wiederkehrende Anfragen und parallele Prozesse schneller verarbeiten zu können und die mögliche Bandbreite des Storages zu erhöhen.
Der Storage-Pool storage_cached umfasst alle Ceph zugeordneten HDDs und dient als eigentlicher Ablageort für Daten im Ceph-Storage.
3. Betrieb
Zuletzt gehen wir noch kurz auf den Betrieb des Ceph-Clusters ein und geben Anwendungsbeispiele.
3.1 Server Betriebssystem
Der vorliegende Ceph-Cluster mit seinen 3 Nodes wurde auf Basis der derzeit aktuellen Debian 9 „Jessie“ Linux Distribution erstellt. Zudem wurde auf den Nodes die frei verfügbare Virtualisierungsplattform Proxmox VE 5 installiert, das mit seinem Repository u.a. aktuelle Pakete für das Ceph-Dateisystem mitbringt. Der Cluster ließe sich dadurch auch direkt als Virtualisierungsumgebung nutzen, was in diesem Anwendungsfall jedoch nicht relevant ist und daher nicht näher betrachtet werden soll.
Das Ceph-Dateisystem liegt in Version 12 „Luminous“ vor.
3.2 iSCSI-Targets
Wie im Kapitel Grundkonzept ausgeführt, wird die iSCSI-Schnittstelle zum Ceph Storage mittels des Linux SCSItargetframework (TGT) bereitgestellt. Die Bedienung erfolgt auf den einzelnen Nodes per Kommandozeile (Linux Shell, root-Login).
Nachstehend werden einige Standard-Aufgaben und ihre Realisierung beschrieben.
3.2.1 Target erstellen
Zum Erstellen eines neuen iSCSI-Targets mit dahinterliegendem Storage sind die folgenden Schritte erforderlich:
- Speicherbereich auf dem Ceph-Storage reservieren: der nachstehende Befehl erzeugt einen 100 GB großen Speicherbereich auf dem Ceph-Storage storage_cached mit Namen iscsi-tgt-vm001-disk1
rbd create –size 102400 storage_cached/iscsi-tgt-vm001-disk1
Zur Prüfung kann der Inhalt des Storage-Pools mit dem folgenden Kommando aufgelistet werden:
rbd –pool storage_cached ls -l - Für den Zugriff per iSCSI wird ein iSCSI-Portal benötigt. Hier kann entweder ein bestehendes Portal genutzt oder ein neues Portal erstellt werden. Im nachstehenden Beispiel wird ein neues iSCSI-Portal erzeugt mit Target-ID 1 und der angegebenen Benennung:
tgtadm –lld iscsi –op new –modetarget–tid 1 -T iqn.2017-11.kk-ceph.de:vm001.disk1.shared.tgt
Die Target-ID muss dabei eindeutig sein, darf also noch nicht im System existieren. Die bereits eingerichteten iSCSI-Portale können mit dem folgenden Kommando angezeigt werden:
tgtadm –lld iscsi –modetarget–op show
Das Schema für die zuvor verwendete IQN-Bezeichnungen lautet:
iqn.YYYY-MM.NAMING_AUTHORITY:UNIQUE_NAME - Neben einem iSCSI-Portal wird nun noch eine LUN benötigt. Im nachstehenden Beispiel wird zum iSCSI-Portal mit Target-ID 1 noch die LUN 1 generiert und mit dem in Schritt 1 erstellten Speicherbereich auf dem Ceph-Storage verknüpft:
tgtadm –lld iscsi –mode logicalunit –op new –tid 1 –lun 1 –bstype rbd –backing-store storage_cached/iscsi-tgt-vm001-disk1 –bsopts „conf=/etc/pve/ceph.conf;id=admin“ - Zuletzt muss noch dastargetgebunden werden.
Im folgenden Beispiel wieder die Target-ID 1:
tgtadm –lld iscsi –op bind –modetarget–tid 1 -I 10.10.12.0/24
Das angegebene Netzwerksegment 10.10.12.0/24 entspricht dabei dem iSCSI-Netzwerk und bestimmt, dass nur iSCSI-Zugriffe aus diesem IP-Bereich Zugriff erhalten.
Damit iSCSI-Targets auch nach einem Reboot oder Neustart des Dienstes automatisch geladen werden, müssen diese in der Konfigurationsdatei /etc/tgt/conf.d/ceph-tgt-shared.conf fest hinterlegt werden. Für das obige Beispiel sieht der Abschnitt in der Konfiguration wie folgt aus:
<target iqn.2017-11.kk-ceph.de:vm001.disk1.shared.tgt>
driver iscsi
bs-type rbd
backing-store storage_cached/iscsi-tgt-vm001-disk1
initiator-address 10.10.12.0/24
</target>
Zum Erstellen des Konfigurationseintrags hilft das Kommando:
tgt-admin -dump
Allerdings müssen die Eigenschaften „driver“ und „bs-type“ händisch ergänzt werden.
Damit das iSCSI-Target von allen 3 Nodes bereitgestellt wird, muss das beschriebene Verfahren auf jedem Node durchgeführt werden!
3.2.2targetlöschen
Zum Löschen eines Targets müssen die zuvor beschriebenen Schritte in umgekehrter Reihenfolge durchlaufen werden. Für das zuvor beschriebene Beispiel sind dies:
- Target-Bindung aufheben:
tgtadm –lld iscsi –op unbind –modetarget–tid 1 -I 10.10.12.0/24 - LUN löschen:
tgtadm –lld iscsi –mode logicalunit –op delete –tid 1 –lun 1 - iSCSI-Portal löschen (falls nicht mehr anderweitig benötigt):
tgtadm –lld iscsi –op delete –modetarget–tid 1 - Ggf. Speicherbereich auf dem Ceph-Storage freigeben (löschen!):
rbd remove storage_cached/iscsi-tgt-vm001-disk1
3.2.3 Speicherbereich vergrößern
Speicherbereiche auf dem Ceph-Storage können mit dem folgenden Kommando vergrößert werden (Fortsetzung des obigen Beispiels, Vergrößerung auf 150 GB Speicherbelegung):
rbd resize –-size 153600 storage_cached/iscsi-tgt-vm001-disk1
Dies darf nur bei inaktiver iSCSI-Verbindung durchgeführt werden und der iSCSI-Dienst des zugehörigen Portal/LUNs muss anschließend neu gestartet werden!
3.2.4 iSCSI-Konfiguration laden
Wie zuvor erläutert müssen dauerhafte iSCSI-Konfigurationen auf jedem Node in der Konfigurationsdatei /etc/tgt/conf.d/ceph-tgt-shared.conf festgelegt werden.
Geänderte Konfiguration können mit dem folgenden Kommando im laufenden Betrieb übernommen werden:
tgt-admin –update ALL
Dies gilt allerdings nur für inaktive Targets! D.h. ein verbundenestargetbleibt weiterhin bestehen und übernimmt die Änderungen erst nach dem nächsten Neustart des iSCSI-Dienstes.
3.2.5 iSCSI-Dienst
Der iSCSI-Dienst wird beim Neustart eines Nodes automatisch geladen.
Im laufenden Betrieb lässt sich der Dienst mit den folgenden Kommandos steuern:
- Dienst beenden:
service tgt stop - Dienst starten:
service tgt start - Status prüfen:
service tgt status - Dienst neu starten:
service tgt restart
3.3 Monitoring
Im Betriebsalltag sollte der Überwachung des Ceph-Clusters und seiner Nodes eine feste Rolle eingeräumt werden. Einerseits müssen Störungen und Ausfälle zeitnah erkannt werden, damit eine Fehlerbehebung und Rückkehr zum Normalbetrieb stattfinden kann. Andererseits sollten aber auch möglichst fortlaufend Nutzungs- und Performance-Daten des Ceph-Storages erhoben werden, um die Speicherbelegung und –verteilung zu erfassen sowie – im Idealfall – bei Leistungseinbrüchen und Engpässen Rückschlüsse auf die Auslöser ziehen zu können.
Auf Kommandozeilenebene helfen für die erste Diagnose die folgenden Befehle:
- Abfrage des Zustands des Ceph-Dateisystems:
ceph health
bzw. mit Detailinformationen (im Fehlerfall)
ceph health detail - Status-Abfrage Ceph:
ceph status - Auflistung der Ceph OSDs mit aktuellem Status:
ceph osd tree - Latenzzeiten der OSDs:
ceph osd perf - Speicherbeledung der OSDs:
ceph osd df plain - Speicherbeledung des Ceph-Storages (aufgeschlüsselt nach Pools):
ceph df
Darüber hinaus erlaubt Ceph Einblick in hunderte von Laufzeitparametern, die eine Analyse bis hin zu kleinsten Details ermöglichen. Als Einstieg sei hier nur das folgende Abfragekommando beispielhaft genannt, das Details zu den Storage-Pools verrät:
rados df –f json-pretty
Mit Monitoring-Software wie Zabbix und dem Visualisierungstool Grafana lassen sich damit Echtzeit-Dashboards erstellen, die detaillierte Einblicke in Zustand und Lastverhalten des Ceph-Clusters bieten, wie in den nachstehenden Ansichten zu sehen ist.
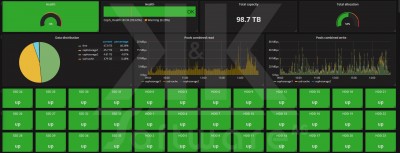
4. Link-Sammlung
Die nachstehende Tabelle listet einige Links zur vertieften Lektüre:
| Link | URL |
| Ceph Homepage | http://ceph.com/ |
| Ceph Dokumentation | http://docs.ceph.com/docs/master/ |
| Proxmox Homepage | https://www.proxmox.com/de/ |
| Proxmox Dokumentation | https://pve.proxmox.com/wiki/Main_Page |
| Konfiguration VMware ESX iSCSI Initiator (Multipath) | https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/ 2/html/block_device_guide/using_an_iscsi_gateway_technology_preview #the_iscsi_initiator_for_vmware_esx |
Die Namensnennung von Firmen oder Markennamen dient lediglich der redaktionellen Verwendung, zur Abgrenzung und zur Kenntlichmachung der Kompatibilität im Rahmen des jeweiligen Geschäftsumfanges. Die Zeichen, Begriffe und Namen sind gegebenenfalls geschützte Marken- und Warenzeichen der jeweiligen Rechteinhaber. Die angebotene Ware ist zu vielen Produkten namhafter Marken kompatibel, es handelt sich aber keinesfalls um Produkte der betreffenden Firmen und Marken!
Autor: Armin Krauß – K&K Software AG
